
엔비디아(www.nvidia.co.kr CEO 젠슨 황)가 새로워진 네모(NeMo) 서비스를 공개했다. 새로운 네모 서비스는 대규모 언어 모델(LLM)이 독점 데이터 소스에서 정확한 정보를 검색하고 사용자 쿼리에 대해 사람과 같은 대화형 답변을 생성할 수 있도록 지원한다. 또한 기업들은 독점 데이터로 LLM을 보강해 추가적인 학습을 하거나 처음부터 다시 시작할 필요 없이 모델의 지식 베이스를 자주 업데이트할 수 있다.
오늘날 사용 가능한 대규모 언어 모델은 풍부한 지식을 갖추고 있지만, 마치 타임캡슐과 같은 특성을 가지고 있다. LLM이 확보한 정보는 처음 훈련될 당시 사용된 데이터로 제한되기 때문이다. 예를 들어, 1년 전에 훈련된 기업의 AI 챗봇을 구동하는 LLM은 기업의 최신 제품 및 서비스에 대한 정보를 갖지 못한다.
엔비디아 네모 서비스를 활용하면 이러한 격차를 해소할 수 있다. 엔비디아 네모는 새롭게 발표된 엔비디아 AI 파운데이션(Foundation) 클라우드 서비스 제품군의 일부로, 기업들은 독점 데이터로 LLM을 보강해 추가적인 학습을 하거나 처음부터 다시 시작할 필요 없이 모델의 지식 베이스를 자주 업데이트할 수 있다.
네모 서비스의 새로운 기능을 사용하면 LLM이 독점 데이터 소스에서 정확한 정보를 검색하고 사용자 쿼리에 대해 사람과 같은 대화형 답변을 생성할 수 있다. 기업들은 해당 기능으로 네모를 통해 애플리케이션에 맞게 정기적으로 업데이트되는 도메인별 지식으로 대규모 언어 모델을 사용자 지정할 수 있다. 이를 통해 기업은 재고, 서비스 등 다양한 분야에서 지속적으로 변화하는 환경에 발맞춰 정확도 높은 AI 챗봇, 엔터프라이즈 검색 엔진, 시장 인텔리전스 도구 등의 기능을 활용할 수 있다.
한편 네모는 언어 모델의 응답에 대한 출처를 인용하는 기능이 포함돼 출력물에 대한 사용자의 신뢰를 높인다. 또한 네모를 사용하는 개발자는 가드레일을 설정해 AI의 전문 영역을 정의함으로써 생성된 응답을 보다 잘 제어할 수 있다.
다크 데이터의 본격 활용
분석가들은 기업 데이터의 약 3분의 2가 활용되지 않는 것으로 추정한다. 소위 ‘다크 데이터(Dark Data)’라고 불리는 이러한 데이터는 방대한 정보에서 의미 있는 인사이트를 얻기 어렵다는 이유로 활용되지 않는다. 이제 기업들은 네모를 사용하여 자연어 쿼리를 통해 다크 데이터로부터 인사이트를 얻을 수 있다.
네모는 모델이 처음에 학습한 기존 데이터 세트와 관계없이, 기업이 진화하는 지식 베이스를 학습하고 대응할 수 있는 모델을 구축할 수 있도록 지원한다. 새로운 정보를 반영하기 위해 LLM을 재학습할 필요 없이, 네모는 엔터프라이즈 데이터 소스를 활용해 최신 세부 정보를 가져올 수 있다. 언어 처리 및 텍스트 생성의 핵심 기능을 수정하지 않고도 추가 정보를 추가하여 모델의 지식 베이스를 확장할 수 있다.
또한 기업은 네모를 사용해 생성형 AI 애플리케이션이 정의된 전문 영역을 벗어난 주제에 대해 의견을 제공하지 않도록 가드레일을 구축할 수 있다.
저작권©올포칩 미디어. 무단전재 및 재배포를 금지합니다.
- 아크로니스, CPU 레벨의 보안 지원 ‘인텔 위협탐지기술’ 탑재아크로니스는 자사의 완성형 통합 솔루션에 적용되는 사이버 보호 기능(complete single-agent cyber protection)과 인텔 TDT를 결합시켰다. 이를 통해 CPU 사용률이 낮아져 컴퓨팅 집약적인 보안 작업(compute-intensive security operations)을 인텔 통합 GPU(Intel integrated GPU)에서 실행하는 동안 아크로니스 최종 고객이 사용하는 생산성 및 사무용 소프트웨어에 더 많은 컴퓨팅 용량을 제공할 수 있다.
 한국레노버, 씽크패드 X1 시리즈 신제품 출시새롭게 출시된 씽크패드 X1 시리즈는 모두 13세대 인텔 코어 프로세서, Intel Evo 플랫폼 기반으로 탁월한 성능과 함께 생산성, 효율성을 극대화한다. OLED 옵션을 지원하는 돌비 비전, AI 노이즈 캔슬링을 탑재한 돌비 보이스와 돌비 애트모스 오디오를 통해 뛰어난 화질과 몰입감 넘치는 오디오 경험을 선사한다
한국레노버, 씽크패드 X1 시리즈 신제품 출시새롭게 출시된 씽크패드 X1 시리즈는 모두 13세대 인텔 코어 프로세서, Intel Evo 플랫폼 기반으로 탁월한 성능과 함께 생산성, 효율성을 극대화한다. OLED 옵션을 지원하는 돌비 비전, AI 노이즈 캔슬링을 탑재한 돌비 보이스와 돌비 애트모스 오디오를 통해 뛰어난 화질과 몰입감 넘치는 오디오 경험을 선사한다 리미니스트리트, 엔드투엔드 아웃소싱 솔루션 '리미니 원’ 출시리미니 원(Rimini ONE)을 통해 고객은 전체 엔터프라이즈 소프트웨어 스택의 유지보수 및 관리를 리미니스트리트에 완전히 아웃소싱할 수 있다. 리미니 원(Rimini ONE)은 고객의 엔터프라이즈 소프트웨어 운영, 유지보수, 보안, 통합에 대한 모든 책임을 리미니스트리트로 이전하고, 고객은 예산과 리소스를 새로운 혁신을 제공하고 비즈니스 가치를 가속화하는 고부가가치 프로젝트에 더 많이 집중할 수 있도록 지원한다.
리미니스트리트, 엔드투엔드 아웃소싱 솔루션 '리미니 원’ 출시리미니 원(Rimini ONE)을 통해 고객은 전체 엔터프라이즈 소프트웨어 스택의 유지보수 및 관리를 리미니스트리트에 완전히 아웃소싱할 수 있다. 리미니 원(Rimini ONE)은 고객의 엔터프라이즈 소프트웨어 운영, 유지보수, 보안, 통합에 대한 모든 책임을 리미니스트리트로 이전하고, 고객은 예산과 리소스를 새로운 혁신을 제공하고 비즈니스 가치를 가속화하는 고부가가치 프로젝트에 더 많이 집중할 수 있도록 지원한다.- 쿤텍, 보안 취약점 통합 관리 솔루션 ‘펜저’ 공급‘펜저(Penzzer)’는 실제 공격을 시뮬레이션하여 공격자의 접근 방식을 식별하는 ‘펜테스트(Pentest)’와 애플리케이션에 임의의 데이터를 무작위로 전송하는 방식으로 취약점을 탐지하는 ‘퍼징(Fuzzing)’을 결합한 통합 솔루션이다. 이러한 접목을 통해 펜테스트만으로는 확인할 수 없는 취약점 정보와 퍼징만으로는 식별할 수 없는 공격 시나리오, 공격 벡터 등을 종합적으로 관리할 수 있으며, 단일 솔루션으로 다양한 장비 및 프로토콜의 취약점을 관리할 수 있는 것이 특징이다.
 NCH 코리아, 음성 공장에 태양광설비 설치NCH의 음성공장에서 생산되는 전력은 제품 생산공정 및 사무실 컴퓨터, 조명 등 생활전력으로 사용하게 된다. NCH는 초도 가동 결과 하루 태양광 전력 생산량은 150kWh 이며, 이는 100W 전구 1500개를 1시간동안 밝힐 수 있는 전력량이다. 이를 통해 NCH는 연간 약 500만원의 전기요금을 절약할 수 있을 것으로 추정된다.
NCH 코리아, 음성 공장에 태양광설비 설치NCH의 음성공장에서 생산되는 전력은 제품 생산공정 및 사무실 컴퓨터, 조명 등 생활전력으로 사용하게 된다. NCH는 초도 가동 결과 하루 태양광 전력 생산량은 150kWh 이며, 이는 100W 전구 1500개를 1시간동안 밝힐 수 있는 전력량이다. 이를 통해 NCH는 연간 약 500만원의 전기요금을 절약할 수 있을 것으로 추정된다. 온세미, 현대자동차그룹 ‘2022 올해의 협력사’ 선정온세미(onsemi)는 글로벌 공급업체의 날(Global Supplier Day) 행사에서 현대자동차그룹으로부터 ‘2022 올해의 협력사’로 선정됐다고 밝혔다. 현대자동차그룹은 온세미를 공급망 탄력성과 제조 지속 가능성을 제공하는 신뢰할 수 있는 생태계의 핵심 기술 공급업체로 인정했다. 온세미는 신뢰할 수 있는 공급업체로서 지능형 전력 및 센싱 솔루션을 제공하여 현대자동차그룹의 목표 달성을 지원한다.
온세미, 현대자동차그룹 ‘2022 올해의 협력사’ 선정온세미(onsemi)는 글로벌 공급업체의 날(Global Supplier Day) 행사에서 현대자동차그룹으로부터 ‘2022 올해의 협력사’로 선정됐다고 밝혔다. 현대자동차그룹은 온세미를 공급망 탄력성과 제조 지속 가능성을 제공하는 신뢰할 수 있는 생태계의 핵심 기술 공급업체로 인정했다. 온세미는 신뢰할 수 있는 공급업체로서 지능형 전력 및 센싱 솔루션을 제공하여 현대자동차그룹의 목표 달성을 지원한다. 엔비디아 옴니버스, 자동차 제조산업 워크플로우 혁신자동차 산업은 가속 컴퓨팅, AI 및 산업 메타버스의 획기적인 발전에 힘입어 디지털 혁명을 겪고 있다. 자동차 제조업체들은 엔비디아 옴니버스(Omniverse) 플랫폼과 AI를 사용해 컨셉 및 스타일링, 디자인 및 엔지니어링, 소프트웨어 및 전자제품, 스마트 팩토리, 자율 주행, 리테일 등 제품 라이프사이클의 모든 단계를 디지털화하고 있다.
엔비디아 옴니버스, 자동차 제조산업 워크플로우 혁신자동차 산업은 가속 컴퓨팅, AI 및 산업 메타버스의 획기적인 발전에 힘입어 디지털 혁명을 겪고 있다. 자동차 제조업체들은 엔비디아 옴니버스(Omniverse) 플랫폼과 AI를 사용해 컨셉 및 스타일링, 디자인 및 엔지니어링, 소프트웨어 및 전자제품, 스마트 팩토리, 자율 주행, 리테일 등 제품 라이프사이클의 모든 단계를 디지털화하고 있다. 딥엑스, 현대차∙기아와 로봇 플랫폼용 AI 반도체 탑재 협력이번 협약은 현대차∙기아에서 상용화를 목표로 개발 중인 로봇플랫폼에 딥엑스의 AI 반도체 기술을 적용하기 위한 기술 협력을 목표로 한다. 이를 위해 양사는 로봇에 사용될 AI 기능을 딥엑스의 AI SoC(System on Chip) 제품에 탑재하고 양산 제품에 실장하기 위해 구동성 및 양산성을 검증해 최종적으로 로보틱스랩이 개발하는 로봇에 해당 AI 기술을 구현할 것이다
딥엑스, 현대차∙기아와 로봇 플랫폼용 AI 반도체 탑재 협력이번 협약은 현대차∙기아에서 상용화를 목표로 개발 중인 로봇플랫폼에 딥엑스의 AI 반도체 기술을 적용하기 위한 기술 협력을 목표로 한다. 이를 위해 양사는 로봇에 사용될 AI 기능을 딥엑스의 AI SoC(System on Chip) 제품에 탑재하고 양산 제품에 실장하기 위해 구동성 및 양산성을 검증해 최종적으로 로보틱스랩이 개발하는 로봇에 해당 AI 기술을 구현할 것이다 마우저, 인피니언의 멀티레벨 스위칭 증폭기 제품 제공MA2304xN MERUS 시리즈는 무선 및 Bluetooth 스피커, 사운드바, 컨퍼런스 및 멀티채널 룸 오디오 시스템용 배터리 전원 설계를 위한 저출력 및 고출력 애플리케이션 모두에서 탁월한 전력 효율성을 제공한다. 해당 제품은 MERUS 멀티레벨 스위칭 증폭기 기술을 탑재하고 있어 히트싱크나 기존 LC 필터 없이 저출력 및 고출력 애플리케이션 모두에서 탁월한 전력 효율성을 제공한다.
마우저, 인피니언의 멀티레벨 스위칭 증폭기 제품 제공MA2304xN MERUS 시리즈는 무선 및 Bluetooth 스피커, 사운드바, 컨퍼런스 및 멀티채널 룸 오디오 시스템용 배터리 전원 설계를 위한 저출력 및 고출력 애플리케이션 모두에서 탁월한 전력 효율성을 제공한다. 해당 제품은 MERUS 멀티레벨 스위칭 증폭기 기술을 탑재하고 있어 히트싱크나 기존 LC 필터 없이 저출력 및 고출력 애플리케이션 모두에서 탁월한 전력 효율성을 제공한다.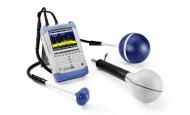 로데슈바르즈, EMV 2023 전시회에서 EMCE 측정 시스템 선보여최신 R&S TSEMF-B2E 등방성 안테나(Isotropic Antenna) 는 700MHz ~ 8GHz의 주파수를 범위를 커버할 수 있어 새로운 무선 서비스 대역까지도 현장에서 간단하고, 정확하게 방출 평가를 수행할 수 있다. 이 R&S TS-EMF 측정 시스템과 로데슈바르즈의 스펙트럼 분석기를 결합하면, 환경 내의 고주파수 EMF(Electromagnetic Field)를 감지할 수 있다.
로데슈바르즈, EMV 2023 전시회에서 EMCE 측정 시스템 선보여최신 R&S TSEMF-B2E 등방성 안테나(Isotropic Antenna) 는 700MHz ~ 8GHz의 주파수를 범위를 커버할 수 있어 새로운 무선 서비스 대역까지도 현장에서 간단하고, 정확하게 방출 평가를 수행할 수 있다. 이 R&S TS-EMF 측정 시스템과 로데슈바르즈의 스펙트럼 분석기를 결합하면, 환경 내의 고주파수 EMF(Electromagnetic Field)를 감지할 수 있다. 온세미, SiC 애플리케이션을 위한 획기적인 시뮬레이션 툴 발표온세미는 개발 주기의 초기 단계에서 시스템 수준 시뮬레이션을 통해 복잡한 전력 전자 애플리케이션에 대한 유의미한 통찰력을 제공하는 온라인 엘리트 전력 시뮬레이터(Elite Power Simulator) 및 셀프 서비스 PLECS 모델 생성기(Self-Service PLECS Model Generator)를 출시했다. 해당 툴들은 비용과 시간이 많이 소요되는 하드웨어 제작 및 테스트 대신, 고객의 애플리케이션에 맞는 EliteSiC 제품 선택을 가능하게 하는 정확한 최신 시뮬레이션을 제공해 전력 전자 엔지니어들이 시간을 단축할 수 있도록 해준다.
온세미, SiC 애플리케이션을 위한 획기적인 시뮬레이션 툴 발표온세미는 개발 주기의 초기 단계에서 시스템 수준 시뮬레이션을 통해 복잡한 전력 전자 애플리케이션에 대한 유의미한 통찰력을 제공하는 온라인 엘리트 전력 시뮬레이터(Elite Power Simulator) 및 셀프 서비스 PLECS 모델 생성기(Self-Service PLECS Model Generator)를 출시했다. 해당 툴들은 비용과 시간이 많이 소요되는 하드웨어 제작 및 테스트 대신, 고객의 애플리케이션에 맞는 EliteSiC 제품 선택을 가능하게 하는 정확한 최신 시뮬레이션을 제공해 전력 전자 엔지니어들이 시간을 단축할 수 있도록 해준다. 엔비디아 호퍼 GPU, AI 수요 증가에 따라 시장 확대트랜스포머 엔진(Transformer Engine)이 내장된 엔비디아 호퍼(Hopper) GPU 컴퓨팅 아키텍처를 기반으로 하는 H100은 생성형 AI, 대규모 언어 모델(LLM) 및 추천 시스템을 개발, 훈련 및 배포하는 데 최적화돼 있다. 이 기술은 H100의 FP8 정밀도를 활용하며 이전 세대 A100에 비해 LLM에서 9배 빠른 AI 훈련과 최대 30배 빠른 AI 추론을 제공한다. H100은 가을부터 글로벌 제조업체의 개별 및 일부 보드 단위로 출하되기 시작했다.
엔비디아 호퍼 GPU, AI 수요 증가에 따라 시장 확대트랜스포머 엔진(Transformer Engine)이 내장된 엔비디아 호퍼(Hopper) GPU 컴퓨팅 아키텍처를 기반으로 하는 H100은 생성형 AI, 대규모 언어 모델(LLM) 및 추천 시스템을 개발, 훈련 및 배포하는 데 최적화돼 있다. 이 기술은 H100의 FP8 정밀도를 활용하며 이전 세대 A100에 비해 LLM에서 9배 빠른 AI 훈련과 최대 30배 빠른 AI 추론을 제공한다. H100은 가을부터 글로벌 제조업체의 개별 및 일부 보드 단위로 출하되기 시작했다. 힐셔, 컴패니언 솔루션 ‘netRAPID 90’ 제품 양산 시작netRAPID 90은 자체 개발한 netX90 SoC 기반의 임베디드형 모듈로, 필요한 프로토콜 스택이 제품에 사전 로드되어 테스트까지 완료된 상태로 제공된다. netRAPID 90은 바로 사용 가능하며 장치 인터페이스 역할을 수행하기 때문에, 고객사에서는 자체 솔루션으로 개발 위험없이 단시간 내에 시장 진입이 가능하다.
힐셔, 컴패니언 솔루션 ‘netRAPID 90’ 제품 양산 시작netRAPID 90은 자체 개발한 netX90 SoC 기반의 임베디드형 모듈로, 필요한 프로토콜 스택이 제품에 사전 로드되어 테스트까지 완료된 상태로 제공된다. netRAPID 90은 바로 사용 가능하며 장치 인터페이스 역할을 수행하기 때문에, 고객사에서는 자체 솔루션으로 개발 위험없이 단시간 내에 시장 진입이 가능하다.- 한국마이크로소프트, ‘커리어 멘토링 데이’ 개최올해로 3회차를 맞는 커리어 멘토링 데이는 3월 8일 세계 여성의 날을 기념해 매년 3월 열린다. 이번 행사는 31일 오후 1시 30분부터 4시간 동안 한국마이크로소프트 본사에서 진행되며, 덕성여대, 서울여대, 성신여대, 숙명여대 등 4개 여자대학이 참여한다. 학생들이 다양한 직무와 다양성 및 포용성 조직 문화를 직접 경험할 수 있도록 마련된 행사에는 권기섭 고용노동부 차관도 참석해 학생들을 격려할 예정이다.
 마이크로칩, 보안 기능을 확장한 maXTouch 터치스크린 컨트롤러 제품군 출시
마이크로칩, 보안 기능을 확장한 maXTouch 터치스크린 컨트롤러 제품군 출시 마우저, 2024년 1분기에 1만 종 이상의 신제품 추가
마우저, 2024년 1분기에 1만 종 이상의 신제품 추가 ST, 집약적 움직임 분석 지원하는 관성 모듈로 엣지-AI 센서 제품군 확장
ST, 집약적 움직임 분석 지원하는 관성 모듈로 엣지-AI 센서 제품군 확장 HMS 네트웍스, AGV를 위한 첨단 무선 기술 지원
HMS 네트웍스, AGV를 위한 첨단 무선 기술 지원 리미니스트리트 ‘2024 리미니스트리트 써밋’, 엔터프라이즈 소프트웨어 유지보수 혁신 지원
리미니스트리트 ‘2024 리미니스트리트 써밋’, 엔터프라이즈 소프트웨어 유지보수 혁신 지원
- ST, 2024 지속가능성 보고서 발표
- 마우저, IoT 및 에너지 하베스팅 설계 세미나 개최
- 매스웍스코리아, 다양한 분야의 AI 인재 발굴 위한 ‘제4회 매트랩 대학생 AI 경진대회’ 개최
- 다쏘시스템과 HD현대중공업, 버추얼 트윈 기반 설계-생산 일관화 통합 플랫폼 구축
- ams OSRAM과 도미넌트 옵토 테크놀로지스, 지능형 RGB LED로 스마트 자동차 실내 조명 구현
- 원프레딕트, 산업 AI 설비관리 솔루션으로 국제전기전력전시회 참가
그래픽 / 영상
 지멘스 EDA, 최첨단 SoC 설계를 위한 혁신적인 에뮬레이션 및 프로토타이핑 솔루션 발표
지멘스 EDA, 최첨단 SoC 설계를 위한 혁신적인 에뮬레이션 및 프로토타이핑 솔루션 발표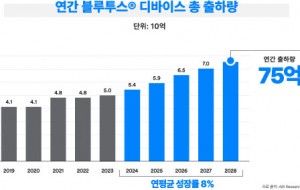 블루투스 지원 기기 출하량, 향후 5년 동안 연평균 8% 성장 전망
블루투스 지원 기기 출하량, 향후 5년 동안 연평균 8% 성장 전망 인터넷의 ‘필터 버블(Filter Bubble)’ 깨부수기
인터넷의 ‘필터 버블(Filter Bubble)’ 깨부수기
많이 본 뉴스
 로데슈바르즈, 스마트바이저와 새로운 EEI 규정 지원 테스트 솔루션 개발
로데슈바르즈, 스마트바이저와 새로운 EEI 규정 지원 테스트 솔루션 개발 시놀로지, DISS 2024 컨퍼런스에서 데이터 보안 관리 솔루션 선보여
시놀로지, DISS 2024 컨퍼런스에서 데이터 보안 관리 솔루션 선보여 GaN FET를 이용한 고성능 클래스-D 오디오 증폭기 설계
GaN FET를 이용한 고성능 클래스-D 오디오 증폭기 설계 쿤텍-시큐어아이씨, 임베디드 분야 보안 강화 지원하는 파트너십 체결
쿤텍-시큐어아이씨, 임베디드 분야 보안 강화 지원하는 파트너십 체결 마이크로소프트, AI 기반 통합 보안 솔루션 ‘코파일럿 포 시큐리티’ 공개
마이크로소프트, AI 기반 통합 보안 솔루션 ‘코파일럿 포 시큐리티’ 공개 콩가텍, 인텔 코어 i3 및 인텔 아톰 x7000RE 프로세서 탑재 SMARC 모듈 출시
콩가텍, 인텔 코어 i3 및 인텔 아톰 x7000RE 프로세서 탑재 SMARC 모듈 출시 키사이트, AI 데이터센터 테스트 플랫폼 출시
키사이트, AI 데이터센터 테스트 플랫폼 출시 미르, AI 기반 자율이동로봇으로 혁신적인 팔레트 물류 자동화 지원
미르, AI 기반 자율이동로봇으로 혁신적인 팔레트 물류 자동화 지원 ST, 2세대 MPU로 지능형 엣지 애플리케이션의 성능 향상 및 산업 탄력성 지원
ST, 2세대 MPU로 지능형 엣지 애플리케이션의 성능 향상 및 산업 탄력성 지원 ST의 RS-485 트랜시버, 산업 자동화, 스마트 빌딩, 로보틱스의 최첨단 애플리케이션 지원
ST의 RS-485 트랜시버, 산업 자동화, 스마트 빌딩, 로보틱스의 최첨단 애플리케이션 지원