
엔비디아(www.nvidia.co.kr )가 새로운 소프트웨어 엔비디아 텐서RT-LLM(NVIDIA TensorRT-LLM)을 출시했다고 밝혔다. 텐서RT-LLM은 텐서RT 딥 러닝 컴파일러로 구성되며 최적화된 커널, 전처리와 후처리 단계, 멀티 GPU/멀티 노드 통신 프리미티브를 포함해 엔비디아 GPU에서 획기적인 성능을 제공한다. 이를 통해 개발자는 C++ 또는 엔비디아 쿠다(CUDA)에 대한 전문적인 배경 지식 없이도 최고의 성능과 빠른 사용자 정의 기능을 제공하는 새로운 대규모 언어 모델을 테스트할 수 있다.
텐서RT-LLM은 대규모 언어 모델이 발전함에 따라 오픈 소스 모듈식 파이썬 API(Python API)를 통해 사용 편의성과 확장성을 개선하고, 쉽게 사용자 맞춤화할 수 있다. 파이썬 API는 새로운 아키텍처와 개선 사항을 정의, 최적화, 실행할 수 있다.
성능 비교
아래 차트를 통해 최신 엔비디아 호퍼 아키텍처에서 텐서RT-LLM이 가져온 성능 향상을 확인할 수 있다. 이는 요약 성능을 평가하는 데 잘 알려진 데이터 세트인 CNN/Daily Mail과 함께 A100과 H100을 사용한 기사의 결과 요약을 보여준다. 기사 요약은 대규모 언어 모델의 다양한 응용 분야 중 하나에 불과하다.
그림 1에서 H100은 단독으로도 A100보다 4배 빠른 속도를 보여준다. 인플라이트 배칭 등 텐서RT-LLM의 성능을 추가하면 속도가 총 8배로 증가해 최고의 처리량을 제공한다.

[그림1] GPT-J-6B에서 A100과 H100 비교(텐서RT-LLM 포함 및 미포함)
최근 메타가 출시한 언어 모델 라마2(Llama 2)는 생성형 AI를 통합하려는 여러 조직에서 널리 사용되고 있다. 이 라마2에서 텐서RT-LLM은 A100 GPU에 비해 추론 성능을 4.6배 가속화할 수 있다.

[그림2] 라마2에서 70B에서 A100과 H100 비교(텐서RT-LLM 포함 및 미포함)
총소유비용과 에너지 효율성 개선
데이터센터의 총소유비용(TCO)과 에너지 소비를 최소화하는 것은 AI를 도입하는 고객의 핵심 목표이다. 특히 연산 요구사항이 폭발적으로 증가하는 대규모 언어 모델의 경우 더욱 중요하다. 고객은 AI 플랫폼 지출과 관련해 하나의 서버 비용만 고려하지 않는다. 오히려 총 자본 비용과 운영 비용을 종합적으로 고려해야 한다.
자본 비용에는 GPU 서버, 관리 헤드 노드(모든 GPU 서버를 조정하는 CPU 서버), 네트워킹 장비(패브릭, 이더넷, 케이블링), 스토리지 비용이 포함된다. 운영 비용에는 데이터센터 IT 인력 비용과 소프트웨어, 장비 유지보수, 데이터센터 임대료, 전기료 등이 포함된다. 데이터센터에서 발생하는 실제 비용을 총체적으로 고려할 때, 성능이 크게 향상되면 장비와 유지보수 요구 사항이 줄어들어 상당한 자본, 운영 비용을 절감할 수 있다.
아래 차트는 GPT-J 6B와 같은 소형 언어 모델에서 8배의 성능 속도 향상으로 A100 기준 대비 총소유비용이 5.3배, 소비 에너지는 5.6배 절감되는 것을 보여준다.

[그림3] GPT-J-6B에서 A100과 H100의 총소유비용과 에너지 효율 절감 수준
대규모 언어 모델 에코시스템의 폭발적 성장
대규모 언어 모델 에코시스템은 새롭고 다양한 모델 아키텍처를 개발하며 빠르게 혁신하고 있다. 대규모 모델은 새로운 기능과 이용 사례를 제시한다. 700억 개의 파라미터로 구성된 메타의 라마2와 같이 가장 크고 진보된 언어 모델은 실시간으로 응답을 제공하기 위해 여러 개의 GPU가 함께 작동된다. 기존에는 대규모 언어 모델 추론에서 최고의 성능을 얻기 위해 개발자가 AI 모델을 다시 작성하고 수동으로 조각으로 분할해 여러 GPU에서 실행을 조정해야 했다.
하지만 텐서RT-LLM은 개별 가중치 행렬을 여러 디바이스에서 분할하는 모델 병렬 처리의 일종인 텐서 병렬 처리(Tensor Parallelism)를 사용한다. 이를 통해 개발자의 개입이나 모델 변경 없이도 각 모델이 NV링크(NVLink)를 통해 연결된 여러 GPU와 서버에서 병렬로 실행돼 대규모 추론을 효율적으로 수행할 수 있게 됐다.
새로운 모델과 모델 아키텍처가 도입됨에 따라 개발자는 텐서RT-LLM에서 오픈 소스로 제공되는 최신 엔비디아 AI 커널을 사용해 모델을 최적화한다. 지원되는 커널 융합에는 컨텍스트와 GPT 모델 실행의 생성 단계를 위한 플래시어텐션(FlashAttention)의 최첨단 실행과 마스킹된 멀티헤드 어텐션 등이 포함된다.
또한 텐서RT-LLM에는 오늘날 프로덕션 환경에서 널리 사용되는 많은 대규모 언어 모델의 최적화되고 바로 실행 가능한 버전이 포함돼 있다. 여기에는 메타의 라마 2, 오픈AI(OpenAI)의 GPT-2 와 GPT-3, 팔콘(Falcon), 모자이크 MPT(Mosaic MPT), 블룸(BLOOM) 등 12가지가 포함되며, 모두 사용이 간편한 텐서RT-LLM 파이썬API로 구현할 수 있다.
이러한 기능을 통해 개발자는 사실상 모든 업계의 요구 사항을 충족하는 맞춤형 대규모 언어 보델을 더 빠르고 정확하게 만들 수 있다.
인플라이트 배칭(In-flight Batching)
오늘날 대규모 언어 모델은 다용도로 사용 가능하다. 하나의 모델을 서로 매우 다르게 보이는 다양한 작업에 단일 모델을 동시에 사용할 수 있다. 챗봇의 간단한 질의응답부터 문서 요약 또는 긴 코드 생성에 이르기까지 워크로드는 매우 복잡하고, 출력의 크기가 몇 배나 달라진다.
이러한 다양성으로 인해 신경망 서비스를 위한 일반적인 최적화 요청을 일괄 처리하고 병렬로 효과적으로 실행하는 것이 어려울 수 있으며, 이로 인해 일부 요청이 다른 요청보다 훨씬 일찍 완료될 수 있다.
이러한 동적 부하를 관리하기 위해, 텐서RT-LLM에는 인플라이트 배칭이라는 최적화된 스케줄링 기법을 탑재했다. 이는 대규모 언어 모델의 전체 텍스트 생성 프로세스가 모델에서 여러 번의 실행 반복으로 세분화될 수 있다는 점을 활용한다.
인플라이트 배칭을 사용하면 전체 요청이 완료될 때까지 기다렸다가 다음 요청 세트로 넘어가는 대신, 텐서RT-LLM 런타임이 완료된 시퀀스를 배치에서 즉시 제거한다. 그런 다음 다른 요청이 아직 전송 중인 동안 새 요청을 실행한다. 인플라이트 배칭과 추가적인 커널 수준 최적화를 통해 GPU 사용량을 개선하고 H100 텐서 코어 GPU의 실제 대규모 언어 모델 요청 벤치마크에서 처리량을 최소 두 배 이상 증가시켜 총소유비용을 최소화하고 에너지 비용을 절감한다.
FP8이 포함된 H100 트랜스포머 엔진
대규모 언어 모델에는 수십억 개의 모델 가중치와 활성화가 포함되며, 일반적으로 각 값이 16비트의 메모리를 차지하는 16비트 부동 소수점(FP16 또는 BF16) 값으로 훈련되고 표현된다. 그러나 추론 시에는 최신 양자화 기술을 사용해 대부분의 모델을 8비트 또는 4비트 정수(INT8 또는 INT4)와 같이 더 낮은 정밀도로 효과적으로 표현할 수 있다.
양자화는 정확도를 유지하면서 모델의 가중치와 활성화의 정밀도를 낮추는 프로세스이다. 정밀도를 낮추면 각 파라미터가 더 작아지고 모델이 GPU 메모리에서 차지하는 공간이 줄어든다. 따라서 동일한 하드웨어로 더 큰 규모의 모델을 추론하면서도 실행 중 메모리 작업에 소요되는 시간을 단축시킨다.
텐서RT-LLM이 탑재된 엔비디아 H100 GPU(H100 GPU)를 사용하면 모델 가중치를 새로운 FP8 형식으로 쉽게 변환하고, 최적화된 FP8 커널을 자동으로 활용하도록 모델을 컴파일할 수 있다. 이는 호퍼 트랜스포머 엔진(Hopper Transformer Engine) 기술을 통해 가능하며, 별도로 모델 코드를 변경할 필요가 없다.
H100에 도입된 FP8 데이터 포맷을 통해 개발자는 모델을 정량화하고 모델 정확도를 저하시키지 않으면서 메모리 소비를 획기적으로 개선한다. FP8 양자화는 INT8 또는 INT4와 같은 다른 데이터 형식에 비해 높은 정확도를 유지하면서도 가장 빠른 성능을 달성하고 가장 간단한 구현을 제공한다.
저작권©올포칩 미디어. 무단전재 및 재배포를 금지합니다.
 인텔, 개발자가 어디서나 AI를 구현할 수 있는 방안 공개인텔은 연례 개발자 행사인 세번째 인텔 이노베이션(Intel Innovation)을 미국 캘리포니아 산호세에서 개최했다고 밝혔다. 인텔은 올해 행사에서 클라이언트, 엣지, 네트워크 및 클라우드에 이르는 모든 워크로드에서 인공지능 접근성을 높이고 사용할 수 있도록 지원하는 다양한 기술을 공개했다.
인텔, 개발자가 어디서나 AI를 구현할 수 있는 방안 공개인텔은 연례 개발자 행사인 세번째 인텔 이노베이션(Intel Innovation)을 미국 캘리포니아 산호세에서 개최했다고 밝혔다. 인텔은 올해 행사에서 클라이언트, 엣지, 네트워크 및 클라우드에 이르는 모든 워크로드에서 인공지능 접근성을 높이고 사용할 수 있도록 지원하는 다양한 기술을 공개했다. 한국레노버, ‘이음 5G를 위한 레노버 테크데이’ 성료한국레노버가 퀄컴코리아와 함께 ‘이음 5G(5G 특화망)를 위한 레노버 테크데이’를 성공적으로 마쳤다. 이번 행사는 업계 최초의 이음 5G 전용 노트북과 태블릿의 국내 출시를 기념해 ‘이음5G를 위한 레노버와 퀄컴의 스마트 기술 및 다양한 국내 구축 사례’를 주제로 진행됐다.
한국레노버, ‘이음 5G를 위한 레노버 테크데이’ 성료한국레노버가 퀄컴코리아와 함께 ‘이음 5G(5G 특화망)를 위한 레노버 테크데이’를 성공적으로 마쳤다. 이번 행사는 업계 최초의 이음 5G 전용 노트북과 태블릿의 국내 출시를 기념해 ‘이음5G를 위한 레노버와 퀄컴의 스마트 기술 및 다양한 국내 구축 사례’를 주제로 진행됐다. AMD, 엣지 혁신을 가속화하는 크리아 K24 SOM 및 스타터 키트 출시AMD는 산업 및 상업용 애플리케이션의 엣지 혁신을 가속화할 수 있는 새로운 크리아(Kria) K24 SOM 및 KD240 드라이브 스타터 키트(Drives Starter Kit)를 출시했다. AMD 크리아 K24 SOM은 비용에 민감한 산업 및 상업용 애플리케이션을 위한 소형 폼팩터 기반의 전력 효율적인 컴퓨팅 솔루션이다.
AMD, 엣지 혁신을 가속화하는 크리아 K24 SOM 및 스타터 키트 출시AMD는 산업 및 상업용 애플리케이션의 엣지 혁신을 가속화할 수 있는 새로운 크리아(Kria) K24 SOM 및 KD240 드라이브 스타터 키트(Drives Starter Kit)를 출시했다. AMD 크리아 K24 SOM은 비용에 민감한 산업 및 상업용 애플리케이션을 위한 소형 폼팩터 기반의 전력 효율적인 컴퓨팅 솔루션이다. AMD, 신규 에픽 8004 프로세서 발표로 4세대 서버 프로세서 제품군 완성AMD가 AMD 에픽 8004 시리즈 프로세서를 선보이며 완성된 4세대 AMD 에픽 프로세서 제품군을 발표했다. "젠 4c" 코어 기반의 AMD 에픽 8004 시리즈 프로세서는 하드웨어 제조사의 효율적이고 차별화된 플랫폼 개발을 지원하며 유통, 제조 및 통신을 포함한 인텔리전트 엣지부터 클라우드 서비스, 스토리지 등을 위한 데이터 센터까지 다양한 애플리케이션 구동에 도움을 준다.
AMD, 신규 에픽 8004 프로세서 발표로 4세대 서버 프로세서 제품군 완성AMD가 AMD 에픽 8004 시리즈 프로세서를 선보이며 완성된 4세대 AMD 에픽 프로세서 제품군을 발표했다. "젠 4c" 코어 기반의 AMD 에픽 8004 시리즈 프로세서는 하드웨어 제조사의 효율적이고 차별화된 플랫폼 개발을 지원하며 유통, 제조 및 통신을 포함한 인텔리전트 엣지부터 클라우드 서비스, 스토리지 등을 위한 데이터 센터까지 다양한 애플리케이션 구동에 도움을 준다. KT-ETRI, 제2회 ‘네트워크 AI 해커톤’에서 AI 인재 발굴이번 행사는 올해 2회째를 맞는 국내 유일의 네트워크 AI 해커톤 대회로, ICT 인재를 확보하고 KT의 네트워크 AI 기술 리더십을 제고하기 위해 마련됐다. 올해는 작년보다 70% 증가한 186개 팀 306명이 참가했다. KT와 ETRI는 데이터 이해도와 모델 창의성, 발표 역량 등을 종합해서 평가해 대상 1개 팀, 최우수상 2개 팀, 우수상 3개 팀을 선정했다.
KT-ETRI, 제2회 ‘네트워크 AI 해커톤’에서 AI 인재 발굴이번 행사는 올해 2회째를 맞는 국내 유일의 네트워크 AI 해커톤 대회로, ICT 인재를 확보하고 KT의 네트워크 AI 기술 리더십을 제고하기 위해 마련됐다. 올해는 작년보다 70% 증가한 186개 팀 306명이 참가했다. KT와 ETRI는 데이터 이해도와 모델 창의성, 발표 역량 등을 종합해서 평가해 대상 1개 팀, 최우수상 2개 팀, 우수상 3개 팀을 선정했다. 인텔, 최대 3배 향상된 대역폭의 썬더볼트5 기술 발표썬더볼트5는 초당 80Gbps의 양방향 대역폭을 지원하며 대역폭 부스트를 활용하면 최고의 디스플레이 경험을 위해 최대 120Gbps를 제공한다. 썬더볼트5는 이러한 개선사항을 바탕으로 현존하는 최고 성능의 솔루션 대비 최대 3배 더 많은 대역폭을 제공해 뛰어난 디스플레이 및 데이터 연결성을 자랑한다. 썬더볼트5는 콘텐츠 제작자와 게이머의 높은 대역폭 요구를 충족할 예정이다.
인텔, 최대 3배 향상된 대역폭의 썬더볼트5 기술 발표썬더볼트5는 초당 80Gbps의 양방향 대역폭을 지원하며 대역폭 부스트를 활용하면 최고의 디스플레이 경험을 위해 최대 120Gbps를 제공한다. 썬더볼트5는 이러한 개선사항을 바탕으로 현존하는 최고 성능의 솔루션 대비 최대 3배 더 많은 대역폭을 제공해 뛰어난 디스플레이 및 데이터 연결성을 자랑한다. 썬더볼트5는 콘텐츠 제작자와 게이머의 높은 대역폭 요구를 충족할 예정이다. ST, 무선 마이크로컨트롤러로 신드콘의 보다 효율적이고 지속가능한 스마트 계량기 구현 지원이 프로젝트는 48MHz에서 동작하는 Arm Cortex-M4 코어를 갖춘 서브 GHz 무선 마이크로컨트롤러인 ST의 고집적 STM32WLE5CC 무선 MCU를 이용하는 신드콘의 인도네시아 첫 번째 구축 사업이다. STM32WLE5가 새롭게 장착된 신드콘의 계량기는 최대 10년 동안 정확한 원격 검침을 지원하는 첨단 배터리 관리 시스템을 내장하고 있다. 계량기는 현재 개선 작업 중이며, 2023년 말까지 설치가 완료될 예정이다.
ST, 무선 마이크로컨트롤러로 신드콘의 보다 효율적이고 지속가능한 스마트 계량기 구현 지원이 프로젝트는 48MHz에서 동작하는 Arm Cortex-M4 코어를 갖춘 서브 GHz 무선 마이크로컨트롤러인 ST의 고집적 STM32WLE5CC 무선 MCU를 이용하는 신드콘의 인도네시아 첫 번째 구축 사업이다. STM32WLE5가 새롭게 장착된 신드콘의 계량기는 최대 10년 동안 정확한 원격 검침을 지원하는 첨단 배터리 관리 시스템을 내장하고 있다. 계량기는 현재 개선 작업 중이며, 2023년 말까지 설치가 완료될 예정이다. 인텔코리아, ‘2023 인텔 게이머 데이’ 개최인텔코리아는 2023 인텔 게이머 데이에서 최신 13세대 인텔 코어 프로세서, 인텔 아크 그래픽 제품 및 해당 제품이 탑재된 다양한 게이밍 제품을 할인된 가격에 제공한다. 행사 기간 내에 인텔 코어 i5, i7, i9 프로세서 기반의 게이밍 노트북을 구매한 고객에게는 오픈마켓별 다양한 혜택을 제공한다.
인텔코리아, ‘2023 인텔 게이머 데이’ 개최인텔코리아는 2023 인텔 게이머 데이에서 최신 13세대 인텔 코어 프로세서, 인텔 아크 그래픽 제품 및 해당 제품이 탑재된 다양한 게이밍 제품을 할인된 가격에 제공한다. 행사 기간 내에 인텔 코어 i5, i7, i9 프로세서 기반의 게이밍 노트북을 구매한 고객에게는 오픈마켓별 다양한 혜택을 제공한다. 마이크로칩, MCU 및 MPU에 머신러닝 손쉽게 통합하는 ‘MPLAB 머신러닝 개발 스위트’ 출시마이크로칩테크놀로지는 간소화된 머신러닝 모델을 개발할 수 있는 통합 워크플로우 MPLAB 머신러닝 개발 스위트를 출시했다. 이 소프트웨어 툴 키트는 마이크로칩의 MCU 및 MPU 제품군 전반에 걸쳐 활용될 수 있어 머신러닝 추론(Inference) 작업을 보다 빠르고 효율적으로 구현할 수 있다.
마이크로칩, MCU 및 MPU에 머신러닝 손쉽게 통합하는 ‘MPLAB 머신러닝 개발 스위트’ 출시마이크로칩테크놀로지는 간소화된 머신러닝 모델을 개발할 수 있는 통합 워크플로우 MPLAB 머신러닝 개발 스위트를 출시했다. 이 소프트웨어 툴 키트는 마이크로칩의 MCU 및 MPU 제품군 전반에 걸쳐 활용될 수 있어 머신러닝 추론(Inference) 작업을 보다 빠르고 효율적으로 구현할 수 있다. 인텔 파운드리 서비스, 타워 세미컨덕터와 함께 신규 美 파운드리 계약 발표이번 협력을 통해 인텔은 타워가 전 세계 고객을 지원할 수 있도록 파운드리 서비스와 300mm 제조 역량을 제공한다. 또한 타워는 美 뉴멕시코 주에 위치한 인텔 생산시설을 활용하게 된다. 타워는 뉴멕시코 시설에 설치할 장비 및 기타 고정 자산 확보 및 소유에 최대 3억달러를 투자할 예정이다. 이를 통해 타워의 미래 성장을 위한 월간 60만 장 이상의 포토레이어 처리 역량을 확보해 첨단 300mm 첨단 아날로그 프로세싱에 대한 예상 고객 수요를 지원할 수 있게 된다.
인텔 파운드리 서비스, 타워 세미컨덕터와 함께 신규 美 파운드리 계약 발표이번 협력을 통해 인텔은 타워가 전 세계 고객을 지원할 수 있도록 파운드리 서비스와 300mm 제조 역량을 제공한다. 또한 타워는 美 뉴멕시코 주에 위치한 인텔 생산시설을 활용하게 된다. 타워는 뉴멕시코 시설에 설치할 장비 및 기타 고정 자산 확보 및 소유에 최대 3억달러를 투자할 예정이다. 이를 통해 타워의 미래 성장을 위한 월간 60만 장 이상의 포토레이어 처리 역량을 확보해 첨단 300mm 첨단 아날로그 프로세싱에 대한 예상 고객 수요를 지원할 수 있게 된다. 키사이트테크놀로지스, ‘키사이트 월드: 테크데이 2023 서울’ 개최키사이트코리아가 ‘키사이트 월드: 테크데이(Keysight World: Tech Day) 2023’을 개최했다. 서울 엘타워에서 개최된 이번 행사는 키사이트가 업계 리더들의 의사 결정을 위해 새롭게 부상하는 기술 동향과 엔지니어링 성공 사례, 솔루션 등 정보를 제공하고 고객들이 직접 확인해 볼 수 있는 행사이다.
키사이트테크놀로지스, ‘키사이트 월드: 테크데이 2023 서울’ 개최키사이트코리아가 ‘키사이트 월드: 테크데이(Keysight World: Tech Day) 2023’을 개최했다. 서울 엘타워에서 개최된 이번 행사는 키사이트가 업계 리더들의 의사 결정을 위해 새롭게 부상하는 기술 동향과 엔지니어링 성공 사례, 솔루션 등 정보를 제공하고 고객들이 직접 확인해 볼 수 있는 행사이다. KT, 캐나다 벡터 연구소와 초거대 AI 협력 논의양사는 AI가 최적의 결과물을 내놓을 수 있게 명령어를 만드는 '프롬프트 엔지니어링(Prompt Engineering)' 등 최신 AI 기술에 관한 공동 리서치를 진행 중이며, 이를 사업에 적용하기 위한 최적의 방법론을 찾는 데 협력하고 있다. 이를 바탕으로 KT는 최신 AI 기술들을 다양한 서비스에 활용하는 방안을 검토 중이다.
KT, 캐나다 벡터 연구소와 초거대 AI 협력 논의양사는 AI가 최적의 결과물을 내놓을 수 있게 명령어를 만드는 '프롬프트 엔지니어링(Prompt Engineering)' 등 최신 AI 기술에 관한 공동 리서치를 진행 중이며, 이를 사업에 적용하기 위한 최적의 방법론을 찾는 데 협력하고 있다. 이를 바탕으로 KT는 최신 AI 기술들을 다양한 서비스에 활용하는 방안을 검토 중이다. 낭만 캠핑 여행에 어울리는 휴대용 가전 IT템 세 가지최근에는 캠핑 여행을 더욱 편리하게 즐기기 위해 캠핑에 최적화된 휴대용 가전 IT 아이템을 사용하는 것이 트렌드가 되었고, IT 업계 또한 이와 같은 흐름에 부응하기 위해 다양한 아이템을 선보이고 있다. 가을 캠핑 여행을 계획하고 있다면, 지금부터 소개하는 세 가지 휴대용 가전 IT 아이템에 주목하자.
낭만 캠핑 여행에 어울리는 휴대용 가전 IT템 세 가지최근에는 캠핑 여행을 더욱 편리하게 즐기기 위해 캠핑에 최적화된 휴대용 가전 IT 아이템을 사용하는 것이 트렌드가 되었고, IT 업계 또한 이와 같은 흐름에 부응하기 위해 다양한 아이템을 선보이고 있다. 가을 캠핑 여행을 계획하고 있다면, 지금부터 소개하는 세 가지 휴대용 가전 IT 아이템에 주목하자. 영국 국가사이버보안센터, 마이크로칩의 PolarFire FPGA를 기반으로 성공적인 보안 검증마이크로칩의 PolarFire 디바이스는 두 배나 높은 전력 효율성과 방위 산업 등급의 보안성, 그리고 업계 최고 수준의 신뢰성을 제공하며 이 분야를 선도하고 있다. 마이크로칩은 크기가 점점 작아지고 비용은 적게 드는 산업용, IoT 및 기타 엣지 컴퓨팅 제품에서 데이터 및 연산 처리(compute capability)역량을 증가시키고, 마이크로칩의 PolarFire 2 FPGA 로드맵을 확장할 예정이다.
영국 국가사이버보안센터, 마이크로칩의 PolarFire FPGA를 기반으로 성공적인 보안 검증마이크로칩의 PolarFire 디바이스는 두 배나 높은 전력 효율성과 방위 산업 등급의 보안성, 그리고 업계 최고 수준의 신뢰성을 제공하며 이 분야를 선도하고 있다. 마이크로칩은 크기가 점점 작아지고 비용은 적게 드는 산업용, IoT 및 기타 엣지 컴퓨팅 제품에서 데이터 및 연산 처리(compute capability)역량을 증가시키고, 마이크로칩의 PolarFire 2 FPGA 로드맵을 확장할 예정이다.
 로지텍, 친환경 패션 브랜드 ‘플리츠마마’와 브랜드 콜라보 진행
로지텍, 친환경 패션 브랜드 ‘플리츠마마’와 브랜드 콜라보 진행 마이크로칩, 우주 애플리케이션 위한 내방사선 PolarFire SoC FPGA 출시
마이크로칩, 우주 애플리케이션 위한 내방사선 PolarFire SoC FPGA 출시 마우저, 미래의 엔지니어 및 혁신가 양성을 위해 Ten80 STEM 챌린지 후원
마우저, 미래의 엔지니어 및 혁신가 양성을 위해 Ten80 STEM 챌린지 후원 델 테크놀로지스, 사이버 복원력 강화한 데이터보호 어플라이언스 신제품 출시
델 테크놀로지스, 사이버 복원력 강화한 데이터보호 어플라이언스 신제품 출시 테스트웍스, ETRI의 메타버스 개발 과제를 위한 3D 데이터 셋 구축 사례 공개
테스트웍스, ETRI의 메타버스 개발 과제를 위한 3D 데이터 셋 구축 사례 공개
- 로지텍, 미니멀 라이프를 즐기자: ‘미니멀테리어’에 최적화된 추천 아이템 3
- 마이크로칩, 임베디드 보안 기능을 간단하게 통합할 수 있는 32비트 마이크로컨트롤러 출시
- 한국마이크로소프트, AI 기술의 미래 조명하는 ‘AI Tour in Seoul’ 개최
- 미루웨어, 국제인공지능대전(AI EXPO) 2024 참가
- 플리어의 T5xx 전문가용 열화상 카메라, 전기시설 점검을 위한 필수 장비로 활용
- 델 테크놀로지스 보고서, 생성형 AI가 기업의 성과 창출에 기여
그래픽 / 영상
 지멘스 EDA, 최첨단 SoC 설계를 위한 혁신적인 에뮬레이션 및 프로토타이핑 솔루션 발표
지멘스 EDA, 최첨단 SoC 설계를 위한 혁신적인 에뮬레이션 및 프로토타이핑 솔루션 발표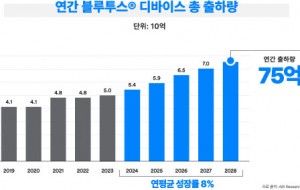 블루투스 지원 기기 출하량, 향후 5년 동안 연평균 8% 성장 전망
블루투스 지원 기기 출하량, 향후 5년 동안 연평균 8% 성장 전망 인터넷의 ‘필터 버블(Filter Bubble)’ 깨부수기
인터넷의 ‘필터 버블(Filter Bubble)’ 깨부수기
많이 본 뉴스
 NXP, MCX W 무선 MCU 시리즈로 엣지 포트폴리오 확장
NXP, MCX W 무선 MCU 시리즈로 엣지 포트폴리오 확장 2025년, 자동차 CSD 애플리케이션에서 In-cell 터치 TFT LCD 점유율 50% 도달
2025년, 자동차 CSD 애플리케이션에서 In-cell 터치 TFT LCD 점유율 50% 도달 로지텍, 하이브리드 워크플레이스를 위한 ‘로지텍 오픈 오피스 데이’ 성료
로지텍, 하이브리드 워크플레이스를 위한 ‘로지텍 오픈 오피스 데이’ 성료 키사이트, 스카일로 비지상 네트워크 인증 프로그램 주도
키사이트, 스카일로 비지상 네트워크 인증 프로그램 주도 Arm, AI 지원 차량 위한 새로운 오토모티브 기술 발표
Arm, AI 지원 차량 위한 새로운 오토모티브 기술 발표 NXP, 개방형 S32 코어라이드 플랫폼으로 SDV 차량 개발 표준화 가속
NXP, 개방형 S32 코어라이드 플랫폼으로 SDV 차량 개발 표준화 가속 콩가텍, 스마트 자동화를 위한 애플리케이션-레디 생태계 선보인다
콩가텍, 스마트 자동화를 위한 애플리케이션-레디 생태계 선보인다 인텔 가우디 2, 최신 MLPerf 벤치마크를 통해 생성형 AI의 지속적인 성능 향상 입증
인텔 가우디 2, 최신 MLPerf 벤치마크를 통해 생성형 AI의 지속적인 성능 향상 입증 콩가텍, µATX 서버 캐리어 보드 및 최신 인텔 제온 프로세서 기반 모듈형 에지 서버 생태계 확장
콩가텍, µATX 서버 캐리어 보드 및 최신 인텔 제온 프로세서 기반 모듈형 에지 서버 생태계 확장 KT, '커스터마이징EZ’로 중소기업 디지털 전환 촉진
KT, '커스터마이징EZ’로 중소기업 디지털 전환 촉진