
AMD가 AMD 인스팅트 MI300X(AMD Instinct MI300X) 가속기 제품군과 AMD 인스팅트 MI300A(AMD Instinct MI300A) APU를 출시했다. 인스팅트 MI300X 가속기는 생성형 AI에 적합한 최고 수준의 메모리 대역폭과 LLM(Large Language Model, 대형 언어 모델) 훈련 및 추론에 필요한 고도화된 성능을 제공한다. 또한, 최신 AMD CDNA 3 아키텍처와 “젠 4(Zen 4)” CPU를 결합한 인스팅트 MI300A APU는 혁신적인 HPC(Hight Performance Computing, 고성능 컴퓨팅) 및 AI 워크로드 처리 능력을 갖췄다.
빅터 펭(Victor Peng) 사장은 “AMD의 최첨단 기술로 탄생한 인스팅트 MI300 시리즈 가속기는 압도적 성능을 바탕으로 향후 대규모 클라우드 및 기업 배포에 활용될 것"이라며 “클라우드 서비스 제공업체나 OEM 및 ODM은 AMD가 제시하는 하드웨어와 소프트웨어 및 개방형 생태계 접근 방식을 활용해 기업이 AI 솔루션을 도입하고 배포할 수 있도록 지원한다”고 덧붙였다.
AMD 인스팅트 MI300X
새로운AMD CDNA 3 아키텍처를 기반으로 하는 AMD 인스팅트 MI300X 가속기는 이전 세대인 AMD 인스팅트 MI250X(AMD Instinct MI250X) 가속기보다 약 40% 더 많은 컴퓨팅 유닛과 1.5배 큰 용량의 메모리를 장착했다. 이론적인 최대 메모리 대역폭 역시 1.7배 높다. 또한, FP8(8비트 부동 소수점) 및 희소성(sparsity) 같은 새로운 포맷을 지원하여 AI 및 HPC 워크로드에도 완벽하게 대비했다.
최근에는 대형 언어 모델의 크기와 복잡성이 지속적으로 확대되고 있어, 이에 걸맞은 대용량 메모리와 컴퓨팅 성능에 대한 요구도 점차 커져가고 있다. AMD 인스팅트 MI300X 가속기는 고부하 AI 워크로드에 필요한 성능을 제공하기 위해 업계 최고 수준의 192GB HBM3 메모리 용량과 초당 최대 5.3 TB(테라바이트) 데이터 처리가 가능한 메모리 대역폭을 지원한다. AMD 인스팅트 시리즈는 업계에서도 손꼽히는 생성형 AI 플랫폼으로, 8개의 MI300X 가속기를 결합한 산업 표준 OCP(Open–Closed Principle; 개방-페쇄 원칙) 디자인을 채택해 HBM3 메모리 용량이 1.5TB에 달한다. 산업 표준 디자인을 채택했기 때문에 OEM사는 기존AI 제품에 MI300X 가속기를 설치해 간편하게 운용할 수 있고 AMD 인스팅트 가속기 기반 서버도 더 빠르게 적용할 수 있다.
이를 활용해 블룸 176B(BLOOM 176B) 같은 대형 언어 모델에서 추론을 실행할 경우, 엔비디아 H100 HGX와 비교해 최대 1.6배 향상된 처리량을 제공한다. 이는 라마 2(Llama2) 같은 70B(70억개의 파라미터) 모델 추론을 단일 가속기에서 실행할 수 있는 업계 유일의 옵션이며, 엔터프라이즈급 LLM을 손쉽게 구축하고 총 소유 비용(TCO; Total Cost of Ownership)을 절감할 수 있도록 지원한다.
AMD 인스팅트 MI300A
AMD 인스팅트 MI300A APU는 세계 최초의 HPC 및 AI용 데이터센터 APU로, 3D 패키징과 4세대 AMD 인피니티 아키텍처(AMD Infinity Architecture)를 활용, 탁월한 워크로드 처리 능력을 발휘한다. 고성능 AMD CDNA 3 GPU 코어와 최신 x86 기반 CPU 코어인 “젠 4”, 128GB용량의 차세대 HBM3 메모리를 결합하여, 기존 AMD 인스팅트 MI250X모델에 비해 FP32 연산HPC 및 AI 워크로드에서 와트당 성능이 약 1.9배 개선되었다.
업계가 에너지 효율성을 최우선시하는데 반해 HPC 및 AI 워크로드는 매우 많은 데이터와 자원을 요구한다. AMD 인스팅트 MI300A APU는 CPU 와 GPU 코어를 단일 패키지에 결합해 효율성을 꾀한 플랫폼이다. 해당 APU의 컴퓨팅 성능으로 최신 AI 모델을 더욱 신속하게 훈련시킬 수 있다. AMD는 자사의 에너지 효율 혁신 목표인 ‘30x25’를 기반으로 2025년까지 AI 훈련 및 HPC용 서버 프로세서와 가속기의 에너지 효율성을 30배로 끌어올릴 계획이다.
저작권©올포칩 미디어. 무단전재 및 재배포를 금지합니다.
 웨스턴디지털, 미디어 및 엔터테인먼트 전문가 지원하는 신제품 출시웨스턴디지털이 ‘샌디스크 프로페셔널(SanDisk Professional)’ 및 ‘샌디스크(SanDisk)’ 브랜드의 신제품을 국내 출시하며 방송, 미디어, 엔터테인먼트 산업을 위한 자사 디지털 콘텐츠 스토리지 솔루션 에코시스템을 강화한다. 이번 샌디스크 프로페셔널 및 샌디스크 브랜드 신제품들은 높은 수준의 효율성, 성능, 신뢰성, 확장성을 제공한다.
웨스턴디지털, 미디어 및 엔터테인먼트 전문가 지원하는 신제품 출시웨스턴디지털이 ‘샌디스크 프로페셔널(SanDisk Professional)’ 및 ‘샌디스크(SanDisk)’ 브랜드의 신제품을 국내 출시하며 방송, 미디어, 엔터테인먼트 산업을 위한 자사 디지털 콘텐츠 스토리지 솔루션 에코시스템을 강화한다. 이번 샌디스크 프로페셔널 및 샌디스크 브랜드 신제품들은 높은 수준의 효율성, 성능, 신뢰성, 확장성을 제공한다. 포티넷, 위협 조사 및 교정을 가속화하는 생성형 AI 어시스턴트 발표포티넷은 40개 이상의 AI 기반 솔루션으로 구성된 포트폴리오에 생성형 AI(GenAI) 어시스턴트 ‘포티넷 어드바이저(Fortinet Advisor)’를 새롭게 추가하게 되었다. 포티넷 어드바이저는 포티넷의 보안 정보 및 이벤트 관리 솔루션인 ‘FortiSIEM’과 포티넷의 보안 오케스트레이션, 자동화, 대응 솔루션인 ‘FortiSOAR’에서 사용할 수 있다.
포티넷, 위협 조사 및 교정을 가속화하는 생성형 AI 어시스턴트 발표포티넷은 40개 이상의 AI 기반 솔루션으로 구성된 포트폴리오에 생성형 AI(GenAI) 어시스턴트 ‘포티넷 어드바이저(Fortinet Advisor)’를 새롭게 추가하게 되었다. 포티넷 어드바이저는 포티넷의 보안 정보 및 이벤트 관리 솔루션인 ‘FortiSIEM’과 포티넷의 보안 오케스트레이션, 자동화, 대응 솔루션인 ‘FortiSOAR’에서 사용할 수 있다. 인텔, 차세대 프로세서 제품군 출시로 ‘AI Everywhere 구현’ 가속화인텔은 데이터 센터부터 클라우드, 네트워크, PC, 그리고 엣지에 이르는 광범위한 인프라 어디서나 AI 솔루션을 구현할 수 있도록 지원하는 업계 최상의 AI 제품 포트폴리오를 출시했다고 발표했다. 인텔은 효율적인 최상의 AI 성능을 제공하는 하드웨어 및 소프트웨어 솔루션을 지원해 고객이 클라우드, 네트워크는 물론 PC와 엣지 인프라까지 AI를 원활하게 구축하고 확장해나갈 수 있도록 지원할 것이다.
인텔, 차세대 프로세서 제품군 출시로 ‘AI Everywhere 구현’ 가속화인텔은 데이터 센터부터 클라우드, 네트워크, PC, 그리고 엣지에 이르는 광범위한 인프라 어디서나 AI 솔루션을 구현할 수 있도록 지원하는 업계 최상의 AI 제품 포트폴리오를 출시했다고 발표했다. 인텔은 효율적인 최상의 AI 성능을 제공하는 하드웨어 및 소프트웨어 솔루션을 지원해 고객이 클라우드, 네트워크는 물론 PC와 엣지 인프라까지 AI를 원활하게 구축하고 확장해나갈 수 있도록 지원할 것이다. 델 테크놀로지스-카카오엔터프라이즈, 멀티 클라우드 비즈니스 활성화 위한 MoU 체결이번 협약을 통해 공동으로 클라우드 비즈니스 모델을 개발하고, 고객들에게 최적의 솔루션을 제공하기 위해 협력할 계획이다. 업계를 선도하는 델 테크놀로지스의 데이터센터 인프라스트럭처 솔루션과 카카오엔터프라이즈의 고성능 클라우드를 결합함으로써 양사 고객들은 멀티 클라우드 환경에서 데이터 자산을 보다 안전하게 보호하며, 서비스 연속성을 보장할 수 있는 안전하고 유연한 IT 인프라 구축이 가능해 졌다.
델 테크놀로지스-카카오엔터프라이즈, 멀티 클라우드 비즈니스 활성화 위한 MoU 체결이번 협약을 통해 공동으로 클라우드 비즈니스 모델을 개발하고, 고객들에게 최적의 솔루션을 제공하기 위해 협력할 계획이다. 업계를 선도하는 델 테크놀로지스의 데이터센터 인프라스트럭처 솔루션과 카카오엔터프라이즈의 고성능 클라우드를 결합함으로써 양사 고객들은 멀티 클라우드 환경에서 데이터 자산을 보다 안전하게 보호하며, 서비스 연속성을 보장할 수 있는 안전하고 유연한 IT 인프라 구축이 가능해 졌다. 버티브, 인텔 가우디3 AI 가속기 플랫폼을 위한 액체 냉각 솔루션 제공인텔 가우디3 AI 가속기는 수냉식 및 공랭식 서버를 모두 지원하며, 버티브 P2P(pumped two-phase) 냉각 인프라를 통해 지원될 예정이다. 이 액체 냉각 솔루션은 17°C~45°C의 시설 용수를 사용하여 최대 160kW의 가속기 전력까지 테스트를 마쳤다. 공랭식 솔루션은 실내 공기 온도가 최대 35°C(95°F)인 데이터센터에 구축할 수 있는 40kW의 열 부하에 대해 테스트를 마쳤다.
버티브, 인텔 가우디3 AI 가속기 플랫폼을 위한 액체 냉각 솔루션 제공인텔 가우디3 AI 가속기는 수냉식 및 공랭식 서버를 모두 지원하며, 버티브 P2P(pumped two-phase) 냉각 인프라를 통해 지원될 예정이다. 이 액체 냉각 솔루션은 17°C~45°C의 시설 용수를 사용하여 최대 160kW의 가속기 전력까지 테스트를 마쳤다. 공랭식 솔루션은 실내 공기 온도가 최대 35°C(95°F)인 데이터센터에 구축할 수 있는 40kW의 열 부하에 대해 테스트를 마쳤다. 삼텍, 새로운 PCIe 6.0 지원 마이크로 엣지 카드 커넥터 출시삼텍(Samtec)의 Generate 고속 에지 카드 소켓(HSEC6-DV 계열)은 64Gbps PAM4(32Gbps NRZ) 애플리케이션과 PCIe 6.0 규격을 지원한다. HSEC6-DV는 마더보드와 애드인 카드 간의 상호 연결 역할을 하는 프로토타입 PCIe 6.0 AI 하드웨어 설계에 사용된다.
삼텍, 새로운 PCIe 6.0 지원 마이크로 엣지 카드 커넥터 출시삼텍(Samtec)의 Generate 고속 에지 카드 소켓(HSEC6-DV 계열)은 64Gbps PAM4(32Gbps NRZ) 애플리케이션과 PCIe 6.0 규격을 지원한다. HSEC6-DV는 마더보드와 애드인 카드 간의 상호 연결 역할을 하는 프로토타입 PCIe 6.0 AI 하드웨어 설계에 사용된다. ST, 소형 및 저전력 소모로 고해상도 제공하는 새로운 글로벌 셔터 이미지 센서 출시ST의 새로운 글로벌 셔터 이미지 센서는 스마트 안경, AR/VR 헤드셋과 같은 기기에 사용하기 좋은 초소형 다이로 탁월한 해상도를 제공한다. 개인용 및 산업용 로보틱스는 물론, 스마트 홈 기기에도 적합하다. ST 센서는 이러한 모든 애플리케이션에 고성능, 소형, 초저전력 소모, 최적화된 비용 등의 이점을 제공한다
ST, 소형 및 저전력 소모로 고해상도 제공하는 새로운 글로벌 셔터 이미지 센서 출시ST의 새로운 글로벌 셔터 이미지 센서는 스마트 안경, AR/VR 헤드셋과 같은 기기에 사용하기 좋은 초소형 다이로 탁월한 해상도를 제공한다. 개인용 및 산업용 로보틱스는 물론, 스마트 홈 기기에도 적합하다. ST 센서는 이러한 모든 애플리케이션에 고성능, 소형, 초저전력 소모, 최적화된 비용 등의 이점을 제공한다 인텔 랩, ‘NeurIPS 2023’에서 AI 혁신 이끌어 갈 연구 프로젝트 31건 발표NeurIPS 2023에서 인텔 랩은 업계 선도적 AI 연구 및 인텔의 ‘AI 에브리웨어(AI Everywhere)’ 비전을 다양한 혁신가 및 학계 리더들과 공유할 계획이다. 인텔 랩은 12개 주요 컨퍼런스 논문 및 19개 워크샵 논문을 포함한 31개 논문을 발표할 예정이다.
인텔 랩, ‘NeurIPS 2023’에서 AI 혁신 이끌어 갈 연구 프로젝트 31건 발표NeurIPS 2023에서 인텔 랩은 업계 선도적 AI 연구 및 인텔의 ‘AI 에브리웨어(AI Everywhere)’ 비전을 다양한 혁신가 및 학계 리더들과 공유할 계획이다. 인텔 랩은 12개 주요 컨퍼런스 논문 및 19개 워크샵 논문을 포함한 31개 논문을 발표할 예정이다. 델 테크놀로지스, AMD 인스팅트 가속기 탑재한 서버로 생성형 AI를 위한 개방형 에코시스템 확장델 역사상 가장 빠르게 성장하고 있는 솔루션인 ‘Dell PowerEdge XE9680’ 서버는 곧 출시 예정인 ‘AMD 인스팅트 MI300X’ 가속기를 지원하며 AI 성능에 대한 폭넓은 선택지를 제공할 예정이다. MI300X 가속기를 탑재한 파워엣지 XE9680 서버는 데이터의 가치를 발굴하고 맞춤형 대형 언어 모델(LLM)들로 비즈니스를 차별화하기 위한 고성능 기능을 지원한다.
델 테크놀로지스, AMD 인스팅트 가속기 탑재한 서버로 생성형 AI를 위한 개방형 에코시스템 확장델 역사상 가장 빠르게 성장하고 있는 솔루션인 ‘Dell PowerEdge XE9680’ 서버는 곧 출시 예정인 ‘AMD 인스팅트 MI300X’ 가속기를 지원하며 AI 성능에 대한 폭넓은 선택지를 제공할 예정이다. MI300X 가속기를 탑재한 파워엣지 XE9680 서버는 데이터의 가치를 발굴하고 맞춤형 대형 언어 모델(LLM)들로 비즈니스를 차별화하기 위한 고성능 기능을 지원한다. AMD, AI PC 시대를 선도하는 새로운 모바일 PC용 프로세서 및 소프트웨어 출시AMD가 ‘AMD 라이젠 8040 시리즈’ 모바일 프로세서를 출시했다. 특히, 일부 신제품에는 통합 NPU인 ‘라이젠 AI’가 한 다이에 탑재되어 이전 모델 대비 최대 1.6배 향상된 AI 프로세싱 성능을 자랑하며, 새로운 프리미엄급 사용 경험 및 AI 지원 능력을 제공한다. AMD는 또, 더욱 탁월한 AI 경험을 위해 라이젠 AI 소프트웨어를 공급해 사용자가 자신의 AI PC에서 손쉽게 머신러닝 모델을 구축하고 배포할 수 있도록 지원한다.
AMD, AI PC 시대를 선도하는 새로운 모바일 PC용 프로세서 및 소프트웨어 출시AMD가 ‘AMD 라이젠 8040 시리즈’ 모바일 프로세서를 출시했다. 특히, 일부 신제품에는 통합 NPU인 ‘라이젠 AI’가 한 다이에 탑재되어 이전 모델 대비 최대 1.6배 향상된 AI 프로세싱 성능을 자랑하며, 새로운 프리미엄급 사용 경험 및 AI 지원 능력을 제공한다. AMD는 또, 더욱 탁월한 AI 경험을 위해 라이젠 AI 소프트웨어를 공급해 사용자가 자신의 AI PC에서 손쉽게 머신러닝 모델을 구축하고 배포할 수 있도록 지원한다. 앤시스, 삼성전자 파운드리 사업부에 전자기 디자인 솔루션 공급양사의 고객은 실리콘-검증된 정확도를 랩터X를 도입함으로써 삼성전자 파운드리의 제조 공정 역량을 활용하여 5G, WiFi, 자동차 및 HPC의 제품 신뢰성과 성능을 향상시킬 수 있다. 랩터X의 정확도는 고밀도 더미 금속 채움을 포함한 여러 까다로운 레이아웃 지오메트리에 있어서도 검증되었으며, 해당 모델은 실리콘 측정과 상관관계를 보였다.
앤시스, 삼성전자 파운드리 사업부에 전자기 디자인 솔루션 공급양사의 고객은 실리콘-검증된 정확도를 랩터X를 도입함으로써 삼성전자 파운드리의 제조 공정 역량을 활용하여 5G, WiFi, 자동차 및 HPC의 제품 신뢰성과 성능을 향상시킬 수 있다. 랩터X의 정확도는 고밀도 더미 금속 채움을 포함한 여러 까다로운 레이아웃 지오메트리에 있어서도 검증되었으며, 해당 모델은 실리콘 측정과 상관관계를 보였다. 마우저, 스마트 홈 기기 개발자를 위한 기술 리소스 사이트 공개마우저는 매터(Matter), 스레드(Thread), 와이파이 6(Wi-Fi 6) 등과 같은 복잡한 네트워크를 쉽게 이해하고 탐색할 수 있는 리소스를 제공하여 전자 설계 엔지니어들이 최신 동향을 파악할 수 있도록 지원한다. 기존에는 상호 연동하기 어려웠던 스마트 홈 시스템을 이제는 함께 동작이 가능하도록 설계할 수 있게 되었다.
마우저, 스마트 홈 기기 개발자를 위한 기술 리소스 사이트 공개마우저는 매터(Matter), 스레드(Thread), 와이파이 6(Wi-Fi 6) 등과 같은 복잡한 네트워크를 쉽게 이해하고 탐색할 수 있는 리소스를 제공하여 전자 설계 엔지니어들이 최신 동향을 파악할 수 있도록 지원한다. 기존에는 상호 연동하기 어려웠던 스마트 홈 시스템을 이제는 함께 동작이 가능하도록 설계할 수 있게 되었다. 사피온, 자율주행 추론용 NPU IP에 대한 ISO 26262 인증 획득사피온은 자율주행 차량이 요구하는 추론 요건 및 안전 설계 요구 사항을 만족하기 위해, ISO26262 기준에 부합하는 관리 프로세스에 맞추어 다양한 방식의 Safety Feature 들을 추가하여, Automotive향 NPU IP를 개발했다. 사피온은 ISO26262 인증을 통해 전장부품의 고장이나 오작동을 최소화하고자 하는 시장 요구에 가장 잘 부합하면서도 포괄적이고 엄격한 프로세스 표준을 수립했다는 평가를 받게 됐다.
사피온, 자율주행 추론용 NPU IP에 대한 ISO 26262 인증 획득사피온은 자율주행 차량이 요구하는 추론 요건 및 안전 설계 요구 사항을 만족하기 위해, ISO26262 기준에 부합하는 관리 프로세스에 맞추어 다양한 방식의 Safety Feature 들을 추가하여, Automotive향 NPU IP를 개발했다. 사피온은 ISO26262 인증을 통해 전장부품의 고장이나 오작동을 최소화하고자 하는 시장 요구에 가장 잘 부합하면서도 포괄적이고 엄격한 프로세스 표준을 수립했다는 평가를 받게 됐다. KT, GLOTEL 2023 에서 ‘5G 미래 비전’ 등 2개 부문 수상KT는 영국 런던에서 열린 ‘글로텔 어워즈(GLOTEL AWARDS) 2023’에서 ▲ 5G 미래 비전, ▲ 올해의 5G 특화망 프로젝트, 2개 부문에서 글로벌 최우수 기업으로 선정되는 쾌거를 이뤘다. 글로텔 어워즈는 글로벌 ICT 리서치 기관 ‘인포마(INFORMA)’가 전 세계의 우수 통신 기업을 대상으로 진행되는 시상식이다.
KT, GLOTEL 2023 에서 ‘5G 미래 비전’ 등 2개 부문 수상KT는 영국 런던에서 열린 ‘글로텔 어워즈(GLOTEL AWARDS) 2023’에서 ▲ 5G 미래 비전, ▲ 올해의 5G 특화망 프로젝트, 2개 부문에서 글로벌 최우수 기업으로 선정되는 쾌거를 이뤘다. 글로텔 어워즈는 글로벌 ICT 리서치 기관 ‘인포마(INFORMA)’가 전 세계의 우수 통신 기업을 대상으로 진행되는 시상식이다.
 로지텍, 친환경 패션 브랜드 ‘플리츠마마’와 브랜드 콜라보 진행
로지텍, 친환경 패션 브랜드 ‘플리츠마마’와 브랜드 콜라보 진행 마이크로칩, 우주 애플리케이션 위한 내방사선 PolarFire SoC FPGA 출시
마이크로칩, 우주 애플리케이션 위한 내방사선 PolarFire SoC FPGA 출시 마우저, 미래의 엔지니어 및 혁신가 양성을 위해 Ten80 STEM 챌린지 후원
마우저, 미래의 엔지니어 및 혁신가 양성을 위해 Ten80 STEM 챌린지 후원 델 테크놀로지스, 사이버 복원력 강화한 데이터보호 어플라이언스 신제품 출시
델 테크놀로지스, 사이버 복원력 강화한 데이터보호 어플라이언스 신제품 출시 테스트웍스, ETRI의 메타버스 개발 과제를 위한 3D 데이터 셋 구축 사례 공개
테스트웍스, ETRI의 메타버스 개발 과제를 위한 3D 데이터 셋 구축 사례 공개
- 로지텍, 미니멀 라이프를 즐기자: ‘미니멀테리어’에 최적화된 추천 아이템 3
- 마이크로칩, 임베디드 보안 기능을 간단하게 통합할 수 있는 32비트 마이크로컨트롤러 출시
- 한국마이크로소프트, AI 기술의 미래 조명하는 ‘AI Tour in Seoul’ 개최
- 미루웨어, 국제인공지능대전(AI EXPO) 2024 참가
- 플리어의 T5xx 전문가용 열화상 카메라, 전기시설 점검을 위한 필수 장비로 활용
- 델 테크놀로지스 보고서, 생성형 AI가 기업의 성과 창출에 기여
그래픽 / 영상
 지멘스 EDA, 최첨단 SoC 설계를 위한 혁신적인 에뮬레이션 및 프로토타이핑 솔루션 발표
지멘스 EDA, 최첨단 SoC 설계를 위한 혁신적인 에뮬레이션 및 프로토타이핑 솔루션 발표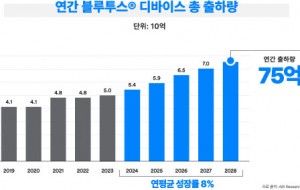 블루투스 지원 기기 출하량, 향후 5년 동안 연평균 8% 성장 전망
블루투스 지원 기기 출하량, 향후 5년 동안 연평균 8% 성장 전망 인터넷의 ‘필터 버블(Filter Bubble)’ 깨부수기
인터넷의 ‘필터 버블(Filter Bubble)’ 깨부수기
많이 본 뉴스
 콩가텍, 인텔 코어 i3 및 인텔 아톰 x7000RE 프로세서 탑재 SMARC 모듈 출시
콩가텍, 인텔 코어 i3 및 인텔 아톰 x7000RE 프로세서 탑재 SMARC 모듈 출시 슈퍼마이크로, X14 서버 제품군에 6세대 인텔 제온 프로세서 탑재 예정
슈퍼마이크로, X14 서버 제품군에 6세대 인텔 제온 프로세서 탑재 예정 인텔, 한스 촹 아시아 태평양 지역 총괄 선임
인텔, 한스 촹 아시아 태평양 지역 총괄 선임 데이터브릭스, 범용 대형언어모델 ‘DBRX’로 효율적인 오픈소스 모델의 새로운 기준 제시
데이터브릭스, 범용 대형언어모델 ‘DBRX’로 효율적인 오픈소스 모델의 새로운 기준 제시 헥사곤, 창원 소재 헥사곤 이노베이션 센터 개관
헥사곤, 창원 소재 헥사곤 이노베이션 센터 개관 다쏘시스템, 2024 독일 하노버 산업박람회에서 버추얼 트윈 혁신 선보인다
다쏘시스템, 2024 독일 하노버 산업박람회에서 버추얼 트윈 혁신 선보인다 아이스아이, 글로벌 SAR 리더십 확장을 위한 기업의 성장 펀딩 라운드 초과 달성
아이스아이, 글로벌 SAR 리더십 확장을 위한 기업의 성장 펀딩 라운드 초과 달성 바이코, WCX 2024에서 48V 아키텍처용 모듈형 전력 변환 솔루션 선보인다
바이코, WCX 2024에서 48V 아키텍처용 모듈형 전력 변환 솔루션 선보인다 마우저, 몰입형 기술 리소스 허브로 미래를 선도하는 설계 엔지니어 지원
마우저, 몰입형 기술 리소스 허브로 미래를 선도하는 설계 엔지니어 지원 AMD, 광범위한 컴퓨팅 엔진 포트폴리오로 AI 가속기 시장 선도
AMD, 광범위한 컴퓨팅 엔진 포트폴리오로 AI 가속기 시장 선도