
엔비디아( www.nvidia.co.kr )가 MLPerf 벤치마크에서 엔비디아 H100 텐서 코어 GPU(NVIDIA H100 Tensore Core GPU)가 생성형 AI를 구동하는 대규모 언어 모델(LLM)에서 최고의 AI 성능을 제공한다고 밝혔다.
최신 MLPerf 트레이닝 벤치마크에서 H100 GPU는 8개의 테스트 모두에서 신기록을 세웠으며, 생성형 Al를 위한 새로운 MLPerf 테스트에서 탁월한 성능을 발휘했다. 이러한 우수성은 개별 가속기와 대규모 서버에서 모두 제공된다. 스타트업 인플렉션(Inflection) AI가 공동 개발하고 GPU 가속 워크로드 전문 클라우드 서비스 제공업체인 코어위브(CoreWeave)가 운영하는 3,584개의 H100 GPU로 구성된 상용 클러스터에서 이 시스템은 11분 이내에 대규모 GPT-3트레이닝 벤치마크를 달성했다.
현존하는 최고의 성능
인플렉션 AI는 이러한 성능을 활용해 최초의 개인용 AI인 Pi(Personal Intelligence)의 기반이 되는 고급 LLM을 구축했다. 인플렉션은 사용자가 간단하고 자연스러운 방식으로 상호 작용할 수 있는 개인용 AI를 개발하는 AI 스튜디오 역할을 하게 된다.
이러한 사용자 경험은 이번 MLPerf 벤치마크에서 입증된 성능을 반영한다. H100 GPU는 대규모 언어 모델, 추천자, 컴퓨터 비전, 의학 이미지 및 음성 인식을 포함한 모든 벤치마크에서 최고의 성능을 선보였다. H100 GPU는 8개의 테스트를 모두 실행한 유일한 칩으로, 엔비디아 AI 플랫폼의 뛰어난 활용성을 입증했다.

또한 코어위브는 클라우드에서 로컬 데이터센터에서 실행되는 AI 슈퍼컴퓨터와 유사한 성능을 제공했다. 이는 코어위브가 사용하는 엔비디아 퀀텀 인피니밴드(Quantum InfiniBand) 네트워킹의 저지연 네트워킹을 입증하는 결과다.
확장되는 엔비디아 AI 에코시스템
이번 라운드에는 약 12개의 기업이 엔비디아 플랫폼에 대한 결과를 제출했다. 이들의 연구는 엔비디아 AI가 업계에서 가장 광범위한 머신 러닝 에코시스템의 지원을 받고 있음을 보여준다. 에이수스(ASUS), 델 테크놀로지스(Dell Technologies), 기가바이트(GIGABYTE), 레노버(Lenovo), QCT를 비롯한 주요 시스템 제조업체에서 제출한 30개 이상의 출품작이 H100 GPU에서 실행됐다.
저작권©올포칩 미디어. 무단전재 및 재배포를 금지합니다.
 마이크로칩, 인도 시장 확대 위해 3억 달러 규모의 투자 계획 발표마이크로칩은 인도 내 사업을 성장시키기 위해 중대한 전략적인 노력을 기울이고 있으며 그 결과, 인도는 반도체 산업의 중요한 비즈니스 및 기술 허브가 되었다. 마이크로칩의 이번 인도 시장 투자는 인도가 글로벌 반도체 산업에서 점점 더 중요한 역할을 감당할 수 있도록 기여하는 동시에 마이크로칩에게도 큰 혜택을 가져올 것이다.
마이크로칩, 인도 시장 확대 위해 3억 달러 규모의 투자 계획 발표마이크로칩은 인도 내 사업을 성장시키기 위해 중대한 전략적인 노력을 기울이고 있으며 그 결과, 인도는 반도체 산업의 중요한 비즈니스 및 기술 허브가 되었다. 마이크로칩의 이번 인도 시장 투자는 인도가 글로벌 반도체 산업에서 점점 더 중요한 역할을 감당할 수 있도록 기여하는 동시에 마이크로칩에게도 큰 혜택을 가져올 것이다. 케이던스, 삼성 파운드리에 ‘인테그리티 3D-IC’ 플랫폼 제공케이던스는 삼성 파운드리와의 협업을 확대하여 하이퍼스케일 컴퓨팅, 5G, 인공지능(AI), 사물인터넷(IoT) 및 모바일 등의 차세대 애플리케이션을 위한 3D-IC 설계 개발을 가속화한다고 발표했다. 이번 협업은 최신 레퍼런스 플루우와 관련 패키지 설계키트를 제공하여 멀티-다이 (Multi-Die) 칩 구현을 발전시킨다.
케이던스, 삼성 파운드리에 ‘인테그리티 3D-IC’ 플랫폼 제공케이던스는 삼성 파운드리와의 협업을 확대하여 하이퍼스케일 컴퓨팅, 5G, 인공지능(AI), 사물인터넷(IoT) 및 모바일 등의 차세대 애플리케이션을 위한 3D-IC 설계 개발을 가속화한다고 발표했다. 이번 협업은 최신 레퍼런스 플루우와 관련 패키지 설계키트를 제공하여 멀티-다이 (Multi-Die) 칩 구현을 발전시킨다. 쿤텍, '2023년 블록체인 민간분야 집중·확산사업' 주관사로 선정쿤텍은 올해 12월까지 블록체인 기반 중소기업을 대상으로 ESG 데이터 플랫폼 'PlanESG(플랜이에스지)'를 통해 공급망 관리, 온실가스 배출량 관리, 탄소배출량 보고서 작성 등의 기능을 제공하여 단일 플랫폼에서 합리적인 비용으로 ESG 분야의 다양한 규제에 효과적으로 대응하고 새로운 성장기회를 확보할 수 있도록 지원할 예정이다.
쿤텍, '2023년 블록체인 민간분야 집중·확산사업' 주관사로 선정쿤텍은 올해 12월까지 블록체인 기반 중소기업을 대상으로 ESG 데이터 플랫폼 'PlanESG(플랜이에스지)'를 통해 공급망 관리, 온실가스 배출량 관리, 탄소배출량 보고서 작성 등의 기능을 제공하여 단일 플랫폼에서 합리적인 비용으로 ESG 분야의 다양한 규제에 효과적으로 대응하고 새로운 성장기회를 확보할 수 있도록 지원할 예정이다. ST, 진단 제어 및 산업용 부하 보호 기능 갖춘 갈바닉 절연 하이사이드 스위치 출시8채널 스위치인 ISO808, ISO808A, ISO808-1, ISO808A-1은 한쪽 면이 접지에 연결된 상태로 용량성, 저항성, 유도성 등 모든 유형의 산업용 부하를 구동한다. 일반적으로 PLC와 산업용 PC 및 CNC 장비에 사용되며, 특히 스마트 공장의 민감한 전자장치에 대한 보호 기능을 강화하기 위해 절연이 필요한 애플리케이션에 적합하다.
ST, 진단 제어 및 산업용 부하 보호 기능 갖춘 갈바닉 절연 하이사이드 스위치 출시8채널 스위치인 ISO808, ISO808A, ISO808-1, ISO808A-1은 한쪽 면이 접지에 연결된 상태로 용량성, 저항성, 유도성 등 모든 유형의 산업용 부하를 구동한다. 일반적으로 PLC와 산업용 PC 및 CNC 장비에 사용되며, 특히 스마트 공장의 민감한 전자장치에 대한 보호 기능을 강화하기 위해 절연이 필요한 애플리케이션에 적합하다. 델 테크놀로지스, 새로운 차원의 업무용 및 게이밍 모니터 신제품 출시이번에 발표한 신제품은 ▲37.5인치 대화면 WQHD+ 패널을 탑재한 ‘델 울트라샤프 38 커브드 USB-C 허브 모니터’ (U3824DW), ▲’에일리언웨어 27인치형 게이밍 모니터’ (AW2724HF), ▲’델 27인치 게이밍 모니터’ (G2724D) 3가지로, 강력한 성능을 발휘하는 프리미엄 업무용 모니터 1종과, 더욱 생생한 게임플레이를 지원하는 게이밍 모니터 2종이다.
델 테크놀로지스, 새로운 차원의 업무용 및 게이밍 모니터 신제품 출시이번에 발표한 신제품은 ▲37.5인치 대화면 WQHD+ 패널을 탑재한 ‘델 울트라샤프 38 커브드 USB-C 허브 모니터’ (U3824DW), ▲’에일리언웨어 27인치형 게이밍 모니터’ (AW2724HF), ▲’델 27인치 게이밍 모니터’ (G2724D) 3가지로, 강력한 성능을 발휘하는 프리미엄 업무용 모니터 1종과, 더욱 생생한 게임플레이를 지원하는 게이밍 모니터 2종이다. AMD, 에뮬레이션 및 프로토타이핑을 위한 세계 최대 용량의 FPGA 기반 적응형 SoC 출시VP1902 적응형 SoC는 점점 더 복잡해지는 반도체 설계 검증을 간소화하도록 설계된 에뮬레이션급 칩렛(Chiplet) 기반 디바이스이다. 이 디바이스는 이전 세대보다 2배 더 많은 용량을 제공하기 때문에 설계자들이 보다 안정적으로 ASIC(Application-Specific Integrated Circuit) 및 SoC 설계를 혁신하고 검증하여 차세대 기술을 보다 신속하게 시장에 출시할 수 있도록 지원한다.
AMD, 에뮬레이션 및 프로토타이핑을 위한 세계 최대 용량의 FPGA 기반 적응형 SoC 출시VP1902 적응형 SoC는 점점 더 복잡해지는 반도체 설계 검증을 간소화하도록 설계된 에뮬레이션급 칩렛(Chiplet) 기반 디바이스이다. 이 디바이스는 이전 세대보다 2배 더 많은 용량을 제공하기 때문에 설계자들이 보다 안정적으로 ASIC(Application-Specific Integrated Circuit) 및 SoC 설계를 혁신하고 검증하여 차세대 기술을 보다 신속하게 시장에 출시할 수 있도록 지원한다. 인텔, ML커먼스의 AI 성능 벤치마크를 통해 AI 경쟁 우위 성능 달성이번 발표는 다양한 딥러닝 모델에 대한 인텔 제품의 높은 성능을 입증했다. 더불어 학습을 위한 가우디2 기반 소프트웨어 및 시스템의 성숙도 또한 대규모 언어 모델인 GPT-3을 통해 검증했다. 가우디2는 GPT-3의 LLM 학습 벤치마크에 성능 결과를 제출한 단 두 개의 반도체 솔루션 중 하나이다.
인텔, ML커먼스의 AI 성능 벤치마크를 통해 AI 경쟁 우위 성능 달성이번 발표는 다양한 딥러닝 모델에 대한 인텔 제품의 높은 성능을 입증했다. 더불어 학습을 위한 가우디2 기반 소프트웨어 및 시스템의 성숙도 또한 대규모 언어 모델인 GPT-3을 통해 검증했다. 가우디2는 GPT-3의 LLM 학습 벤치마크에 성능 결과를 제출한 단 두 개의 반도체 솔루션 중 하나이다. 한국레노버, 세계 최초 OLED 듀얼 스크린 탑재한 ‘요가북 9i’ 국내 출시레노버 8세대 요가의 플래그십 모델인 요가북 9i는 컨버터블 폼팩터의 장점을 극대화하는 ‘멀티모드+’ 기능을 탑재해 멀티태스킹 생산성을 높인 제품이다. ▲북 모드 ▲디스플레이 모드 ▲텐트 모드 ▲태블릿 모드 등 사용 환경에 맞는 다양한 모드와 폴리오 스탠드, 키보드 및 디지털 펜 3 등 악세서리를 사용해 크리에이티브, 게이밍 및 학습 등 여러 작업에서 활용도 높게 사용할 수 있다.
한국레노버, 세계 최초 OLED 듀얼 스크린 탑재한 ‘요가북 9i’ 국내 출시레노버 8세대 요가의 플래그십 모델인 요가북 9i는 컨버터블 폼팩터의 장점을 극대화하는 ‘멀티모드+’ 기능을 탑재해 멀티태스킹 생산성을 높인 제품이다. ▲북 모드 ▲디스플레이 모드 ▲텐트 모드 ▲태블릿 모드 등 사용 환경에 맞는 다양한 모드와 폴리오 스탠드, 키보드 및 디지털 펜 3 등 악세서리를 사용해 크리에이티브, 게이밍 및 학습 등 여러 작업에서 활용도 높게 사용할 수 있다. kt cloud, '클라우드 기반 NPU 인프라' 국내 최초 상용화kt cloud가 리벨리온과 협력하여 글로벌 시장에서도 고성능을 인정받은 NPU ‘아톰’을 탑재한 클라우드 기반 NPU 인프라를 최초로 상용화했다. 정부가 추진하는 ‘K-클라우드 프로젝트’ 중 국산 AI 반도체 개발, 이를 데이터센터에 적용해 국내 클라우드 경쟁력을 강화한다는 정책 등에 가장 발 빠르게 대응하고 있는 것이다.
kt cloud, '클라우드 기반 NPU 인프라' 국내 최초 상용화kt cloud가 리벨리온과 협력하여 글로벌 시장에서도 고성능을 인정받은 NPU ‘아톰’을 탑재한 클라우드 기반 NPU 인프라를 최초로 상용화했다. 정부가 추진하는 ‘K-클라우드 프로젝트’ 중 국산 AI 반도체 개발, 이를 데이터센터에 적용해 국내 클라우드 경쟁력을 강화한다는 정책 등에 가장 발 빠르게 대응하고 있는 것이다. 한국레노버, 새로운 차원의 성능을 지원하는 씽크스테이션 신제품 출시새로 출시된 제품은 ▲씽크스테이션 PX ▲씽크스테이션 P7 ▲씽크스테이션 P5 3종이다. 기존과 전혀 다른 혁신적 본체 설계와 첨단 방열 시스템이 적용되고, 극강의 고성능 컴퓨팅 워크로드 수요에 부응하도록 디자인됐다. 최대 120개 코어의 최신 인텔 프로세서와 엔비디아 고성능 RTX 프로페셔널 GPU를 지원한다.
한국레노버, 새로운 차원의 성능을 지원하는 씽크스테이션 신제품 출시새로 출시된 제품은 ▲씽크스테이션 PX ▲씽크스테이션 P7 ▲씽크스테이션 P5 3종이다. 기존과 전혀 다른 혁신적 본체 설계와 첨단 방열 시스템이 적용되고, 극강의 고성능 컴퓨팅 워크로드 수요에 부응하도록 디자인됐다. 최대 120개 코어의 최신 인텔 프로세서와 엔비디아 고성능 RTX 프로페셔널 GPU를 지원한다. 노르딕 세미컨덕터, 새로운 nRF91 시리즈 SiP 출시와 함께 하드웨어, 소프트웨어, 툴, nRF 클라우드 서비스 및 지원 등 완벽한 셀룰러 IoT 솔루션 제공수상 경력에 빛나는 입증된 nRF91 시리즈 SiP 기반 새로운 제품과 함께 구성된 노르딕의 새로운 셀룰러 IoT 제품은 노르딕이 설계, 관리 및 공급하는 칩셋과 모듈, 그리고 소프트웨어 및 서비스를 통해 보다 간단하고, 안정적으로 비용 효율적인 설계를 구현할 수 있도록 지원한다. 개발에 필요한 모든 요소들이 포함된 세계적 수준의 포괄적인 셀룰러 IoT 솔루션이 단일 공급업체를 통해 제공되는 것은 이번이 처음이다.
노르딕 세미컨덕터, 새로운 nRF91 시리즈 SiP 출시와 함께 하드웨어, 소프트웨어, 툴, nRF 클라우드 서비스 및 지원 등 완벽한 셀룰러 IoT 솔루션 제공수상 경력에 빛나는 입증된 nRF91 시리즈 SiP 기반 새로운 제품과 함께 구성된 노르딕의 새로운 셀룰러 IoT 제품은 노르딕이 설계, 관리 및 공급하는 칩셋과 모듈, 그리고 소프트웨어 및 서비스를 통해 보다 간단하고, 안정적으로 비용 효율적인 설계를 구현할 수 있도록 지원한다. 개발에 필요한 모든 요소들이 포함된 세계적 수준의 포괄적인 셀룰러 IoT 솔루션이 단일 공급업체를 통해 제공되는 것은 이번이 처음이다. 인텔 랩, 텍스트로 360도 이미지 생성 가능한 AI 확산 모델 공개인텔 랩은 블록케이드 랩(Blockade Labs)과 협력해 생성형 인공지능을 사용해 사실적인 3D 시각 콘텐츠를 제작하는 새로운 확산 모델인 LDM3D를 공개했다. LDM3D는 확산 프로세스를 사용해 depth map을 생성하며, 선명하고 몰입감 있는 360도 3D 이미지를 생성한다. LMD3D는 콘텐츠 제작, 메타버스 애플리케이션, 디지털 경험의 혁신을 통해 엔터테인먼트, 게임, 건축, 디자인에 이르기까지 다양한 산업을 바꿀 잠재력을 가지고 있다.
인텔 랩, 텍스트로 360도 이미지 생성 가능한 AI 확산 모델 공개인텔 랩은 블록케이드 랩(Blockade Labs)과 협력해 생성형 인공지능을 사용해 사실적인 3D 시각 콘텐츠를 제작하는 새로운 확산 모델인 LDM3D를 공개했다. LDM3D는 확산 프로세스를 사용해 depth map을 생성하며, 선명하고 몰입감 있는 360도 3D 이미지를 생성한다. LMD3D는 콘텐츠 제작, 메타버스 애플리케이션, 디지털 경험의 혁신을 통해 엔터테인먼트, 게임, 건축, 디자인에 이르기까지 다양한 산업을 바꿀 잠재력을 가지고 있다. 마이크로소프트, 양자 슈퍼컴퓨터 혁신 가속화 위한 로드맵 발표마이크로소프트가 과학적 발견을 가속화하기 위한 새로운 양자 서비스를 공개하고, 양자 슈퍼컴퓨터 구축을 위한 로드맵을 발표했다. 이날 화학 회사가 신소재 연구 및 개발 속도를 높일 수 있도록 돕는 ‘애저 퀀텀 엘리먼트(Azure Quantum Elements)’와 양자기술에 인공지능(AI)을 적용한 ‘애저 퀀텀 코파일럿(Copilot in Azure Quantum)’을 소개했다.
마이크로소프트, 양자 슈퍼컴퓨터 혁신 가속화 위한 로드맵 발표마이크로소프트가 과학적 발견을 가속화하기 위한 새로운 양자 서비스를 공개하고, 양자 슈퍼컴퓨터 구축을 위한 로드맵을 발표했다. 이날 화학 회사가 신소재 연구 및 개발 속도를 높일 수 있도록 돕는 ‘애저 퀀텀 엘리먼트(Azure Quantum Elements)’와 양자기술에 인공지능(AI)을 적용한 ‘애저 퀀텀 코파일럿(Copilot in Azure Quantum)’을 소개했다. AMD 에픽 임베디드 시리즈 프로세서, 새로운 HPE 알레트라 스토리지 MP 지원HPE 알레트라 스토리지 MP는 성능 및 용량을 독립적으로 확장할 수 있는 동일 하드웨어 기반으로 여러 스토리지 프로토콜을 사용하는 분산 인프라를 지원한다. HPE 알레트라 스토리지 MP는 블록 및 파일 저장소를 구성할 수 있어 고객들이 작업부하 및 스토리지 프로토콜과 상관없이 HPE 그린레이크(GreenLake) 엣지-클라우드 플랫폼을 통해 데이터 및 스토리지 서비스를 구축, 관리 및 오케스트레이션할 수 있도록 지원한다.
AMD 에픽 임베디드 시리즈 프로세서, 새로운 HPE 알레트라 스토리지 MP 지원HPE 알레트라 스토리지 MP는 성능 및 용량을 독립적으로 확장할 수 있는 동일 하드웨어 기반으로 여러 스토리지 프로토콜을 사용하는 분산 인프라를 지원한다. HPE 알레트라 스토리지 MP는 블록 및 파일 저장소를 구성할 수 있어 고객들이 작업부하 및 스토리지 프로토콜과 상관없이 HPE 그린레이크(GreenLake) 엣지-클라우드 플랫폼을 통해 데이터 및 스토리지 서비스를 구축, 관리 및 오케스트레이션할 수 있도록 지원한다.
 마이크로칩, 항공우주 및 방위산업 위해 내방사선 MCU 포트폴리오 확장, 32비트 SAMD21RT 출시
마이크로칩, 항공우주 및 방위산업 위해 내방사선 MCU 포트폴리오 확장, 32비트 SAMD21RT 출시 슈퍼마이크로, ISC 2024에서 HPC와 AI 환경에 최적화된 솔루션 선보여…
슈퍼마이크로, ISC 2024에서 HPC와 AI 환경에 최적화된 솔루션 선보여… 마우저, 산업 및 의료, 로봇 애플리케이션을 위한 AMD/자일링스의 크리아(Kria) K24 SOM 공급
마우저, 산업 및 의료, 로봇 애플리케이션을 위한 AMD/자일링스의 크리아(Kria) K24 SOM 공급 인텔, PC간 초고속 전송 가능하게 하는 썬더볼트 쉐어 발표
인텔, PC간 초고속 전송 가능하게 하는 썬더볼트 쉐어 발표 싸이타임, AI 데이터센터를 위한 통합 클럭 칩으로 정밀 타이밍 기술 발전
싸이타임, AI 데이터센터를 위한 통합 클럭 칩으로 정밀 타이밍 기술 발전
- 어플라이드 머티어리얼즈, 회계연도 2024년 2분기 실적 발표
- 엔비디아, 생성형 AI 통해 HPC 연구 가속화
- 자이스, ‘당신에겐 더 선명하게 보입니다’ 신규 캠페인 론칭
- 피커링 인터페이스의 새로운 마이크로웨이브 멀티플렉서 스위치, 최대 40GHz의 대역폭 제공
- 노르딕 세미컨덕터, nRF 클라우드 디바이스 관리 서비스 공식 출시
- AI가 여는 미래 일자리의 변화와 혁신, 마이크로소프트와 링크드인의 2024 업무동향지표
그래픽 / 영상
 전 세계 반도체 재료 시장, 2023년 전년 대비 8.2% 하락
전 세계 반도체 재료 시장, 2023년 전년 대비 8.2% 하락 게임 스트리머와 콘텐츠 크리에이터를 위한 추천 아이템 3
게임 스트리머와 콘텐츠 크리에이터를 위한 추천 아이템 3 2024년 1분기 전세계 실리콘 웨이퍼 출하량 5% 감소
2024년 1분기 전세계 실리콘 웨이퍼 출하량 5% 감소많이 본 뉴스
 슈퍼마이크로, 엔비디아 기반 풀스택 생성형 AI 슈퍼클러스터 3종 출시
슈퍼마이크로, 엔비디아 기반 풀스택 생성형 AI 슈퍼클러스터 3종 출시 콩가텍, µATX 서버 캐리어 보드 및 최신 인텔 제온 프로세서 기반 모듈형 에지 서버 생태계 확장
콩가텍, µATX 서버 캐리어 보드 및 최신 인텔 제온 프로세서 기반 모듈형 에지 서버 생태계 확장 데이터브릭스, 범용 대형언어모델 ‘DBRX’로 효율적인 오픈소스 모델의 새로운 기준 제시
데이터브릭스, 범용 대형언어모델 ‘DBRX’로 효율적인 오픈소스 모델의 새로운 기준 제시 ams OSRAM과 도미넌트 옵토 테크놀로지스, 지능형 RGB LED로 스마트 자동차 실내 조명 구현
ams OSRAM과 도미넌트 옵토 테크놀로지스, 지능형 RGB LED로 스마트 자동차 실내 조명 구현 글로벌 퍼블릭 디스플레이 출하량, 2024년 둔화 전망
글로벌 퍼블릭 디스플레이 출하량, 2024년 둔화 전망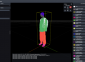 테스트웍스, ETRI의 메타버스 개발 과제를 위한 3D 데이터 셋 구축 사례 공개
테스트웍스, ETRI의 메타버스 개발 과제를 위한 3D 데이터 셋 구축 사례 공개 2024년 1분기 머큐리 리서치 x86 프로세서 점유율 보고서
2024년 1분기 머큐리 리서치 x86 프로세서 점유율 보고서 로데슈바르즈, 획기적인 성능으로 무장한 R&S NGC100 파워 서플라이 제품군 신규 출시
로데슈바르즈, 획기적인 성능으로 무장한 R&S NGC100 파워 서플라이 제품군 신규 출시 IMDT와 Hailo가 합작하여 최고의 실시간 성능을 위한 엣지 AI 솔루션 출시
IMDT와 Hailo가 합작하여 최고의 실시간 성능을 위한 엣지 AI 솔루션 출시 2024년, 디스플레이 글래스 산업 공급부족 우려
2024년, 디스플레이 글래스 산업 공급부족 우려