
엔비디아(www.nvidia.co.kr CEO 젠슨 황)가 대규모 언어 모델(LLM)의 크기와 복잡성이 지속적으로 급증함에 따라 최대 30%의 훈련 속도 향상을 제공하는 네모 메가트론(NeMo Megatron) 프레임워크의 업데이트를 발표했다. 이번 업데이트는 두 가지 선구적인 기술과 여러 GPU에서 LLM 훈련을 최적화하고 확장하는 하이퍼 파라미터(hyper parameter) 도구를 포함한다. 이를 통해 엔비디아 AI 플랫폼으로 모델을 훈련하고 구축할 수 있는 새로운 기능을 제공한다.
1,760억 개의 파라미터(parameter)를 가진 세계 최대 오픈 사이언스, 오픈 액세스 다국어 언어 모델인 블룸(BLOOM)은 최근 엔비디아 AI 플랫폼에서 훈련돼 46개 언어와 13개 프로그래밍 언어로 텍스트 생성을 가능하게 했다. 또한 엔비디아 AI 플랫폼은 5,300억 개의 파라미터를 포함하는 가장 강력한 변환기 언어 모델인 메가트론-튜링 NLG 모델(MT-NLG)을 지원한다.
LLM은 텍스트에서 학습하는 최대 수조 개의 파라미터를 포함하는 오늘날 가장 중요한 첨단 기술 중 하나다. 하지만 이를 개발하려면 심층적인 기술 전문 지식, 분산된 인프라, 전체 스택 접근 방식이 필요해 비용과 시간이 많이 든다. 그러나 실시간 콘텐츠 생성, 텍스트 요약, 고객 서비스 챗봇, 대화형 AI 인터페이스를 위한 질문과 답변을 발전시키는 데 있어 큰 이점을 갖는다.
AI 커뮤니티는 LLM을 발전시키기 위해 메가트론(Megatron)-LM, 에이펙스(Apex), 그리고 기타 GPU 가속 라이브러리를 포함하는 엔비디아 AI 플랫폼을 기반으로 하는 마이크로소프트 딥스피드(Microsoft DeepSpeed), Colossal-AI, 허깅 페이스 빅사이언스(Hugging Face BigScience), 페어스케일(Fairscale) 같은 도구의 혁신을 이어가고 있다.
네모 메가트론의 최신 업데이트는 220억에서 1조 파라미터에 이르는 크기의 GPT-3 모델 훈련 속도를 30% 향상시킨다. 이는 1,024개의 엔비디아 A100 GPU를 사용해 1,750억 개의 파라미터 모델에 대한 훈련을 24일 만에 수행하도록 한다. 즉, 결과 도출 시간을 10일 또는 GPU 컴퓨팅 시간으로 약 250,000 시간 단축할 수 있다.
네모 메가트론은 빠르고 효율적이며 사용하기 쉬운 엔드 투 엔드 컨테이너형 프레임워크이다. 데이터 수집, 대규모 모델 훈련, 업계 표준 벤치마크에 대한 모델 평가, 지연 시간(레이턴시)과 처리량 성능에 대한 최첨단 추론이 가능하다.
이를 통해 LLM 훈련과 추론을 다양한 GPU 클러스터 구성에서 쉽게 재현할 수 있다. 현재 얼리 액세스 고객에게 엔비디아 DGX 슈퍼POD(SuperPOD), 엔비디아 DGX 파운드리(Foundry), 마이크로소프트 애저(Microsoft Azure) 클라우드 플랫폼을 제공한다. 또한 다른 클라우드 플랫폼에 대한 지원도 제공될 예정이다.
더불어 사용자에게 엔비디아 가속 인프라의 실습 랩 카탈로그에 대한 단기 액세스를 제공하는 무료 프로그램인 엔비디아 런치패드(LaunchPad)에서 기능을 체험할 수 있다.
저작권©올포칩 미디어. 무단전재 및 재배포를 금지합니다.
- 롯데마트, 오라클 데이터베이스 유지보수 서비스를 리미니스트리트로 전환롯데마트는 사업 성장과 관련된 전략 프로젝트에 자원을 집중하고자 했으며 급변하는 유통 사업을 더 잘 관리하기 위해 보다 실질적인 데이터베이스 유지보수 서비스가 필요했다. 롯데마트는 제공되는 높은 서비스 품질을 바탕으로 지원 서비스를 최적화하기 위해 리미니스트리트를 선택했다.
 콩가텍, Micro-ATX 폼팩터 규격의 고성능 COM-HPC 캐리어 보드 출시프로세서 소켓 및 벤더에 구애받지 않는 이 보드는 COM-HPC 클라이언트 사이즈 A, B, C의 모든 고성능 컴퓨터 온 모듈에 장착이 가능해 OEM 설계를 더욱 유연하고 오래 유지시킨다. 콩가텍의 12세대 인텔 코어 프로세서 기반 COM-HPC 모듈은 전 제품에서 뛰어난 확장성을 지원하며 14가지의 최상급 성능을 제공한다.
콩가텍, Micro-ATX 폼팩터 규격의 고성능 COM-HPC 캐리어 보드 출시프로세서 소켓 및 벤더에 구애받지 않는 이 보드는 COM-HPC 클라이언트 사이즈 A, B, C의 모든 고성능 컴퓨터 온 모듈에 장착이 가능해 OEM 설계를 더욱 유연하고 오래 유지시킨다. 콩가텍의 12세대 인텔 코어 프로세서 기반 COM-HPC 모듈은 전 제품에서 뛰어난 확장성을 지원하며 14가지의 최상급 성능을 제공한다.- 로옴, 최고 수준의 안정성을 실현한 첨단 ADAS용 DC/DC 컨버터 IC 개발로옴은 자동차의 센서 및 카메라를 비롯한 ADAS 및 인포테인먼트 등 고기능화되는 차량용 애플리케이션을 위한 강압 DC/DC 컨버터 IC, BD9S402MUF-C를 개발했다고 밝혔다. 이 제품은 고성능화되는 SoC 및 마이컴의 2차측 전원에서 요구되는 소형 사이즈와 4A의 출력전류 및 2MHz 이상 스위칭 동작으로 0.6V 저전압 출력에 대응한다.
 인피니언, 배터리없는 스마트락을 가능하게 하는 싱글칩 솔루션 출시이 솔루션의 핵심은 NFC 프론트엔드를 내장한 프로그래머블 32비트 ARM Cortex-M0 마이크로컨트롤러이다. 파워 제너레이션과 H-브리지를 통합한 NAC1080을 사용하면 소수의 부품만으로 소형 스마트락을 개발할 수 있다. 또한 NAC1080은 AES128 가속화기와 참 난수 생성기를 내장하여 극히 낮은 전력 소모로 데이터 암호화 및 암호해독이 가능하다.
인피니언, 배터리없는 스마트락을 가능하게 하는 싱글칩 솔루션 출시이 솔루션의 핵심은 NFC 프론트엔드를 내장한 프로그래머블 32비트 ARM Cortex-M0 마이크로컨트롤러이다. 파워 제너레이션과 H-브리지를 통합한 NAC1080을 사용하면 소수의 부품만으로 소형 스마트락을 개발할 수 있다. 또한 NAC1080은 AES128 가속화기와 참 난수 생성기를 내장하여 극히 낮은 전력 소모로 데이터 암호화 및 암호해독이 가능하다.- 앤시스, 제품 설계 및 개발 지원 ‘앤시스 2022 R2’ 출시앤시스 2022 R2는 예측 가능 범위의 정확한 분석, 인공지능/머신 러닝(AI/ML) 최적화 및 까다로운 엔지니어링 과제를 해결하는 데 필요한 확장형 플랫폼을 제공한다. 오늘날 제품 설계 환경은 극도로 복잡해진 덕분에 반도체 칩의 미세한 결함에서부터, 우주 발사체에 실리는 글로벌 운영 환경에 이르기까지 모든 영역에 대한 통찰 역량을 확보해야 하는 상황이다.
 넥스페리아, 고효율의 웨이퍼 레벨 12V, 30V MOSFET 출시이 MOSFET 제품들은 스마트폰, 스마트 시계, 보청기 및 이어폰 등 고도로 소형화된 전자 제품에 이상적이며, 시스템 전력 수요를 증가시키는 여러가지 다양한 지능형 기능이 추가되는 추세를 지원한다. 이 제품들의 RDS(on)은 경쟁 디바이스들보다 최대 25% 뛰어나기 때문에 에너지 손실을 최소화하고 부하 스위칭 및 배터리 관리 효율성을 높여준다. 뛰어난 성능은 자체 발열을 줄여 웨어러블 장치에서 사용자의 편리성을 향상시킨다.
넥스페리아, 고효율의 웨이퍼 레벨 12V, 30V MOSFET 출시이 MOSFET 제품들은 스마트폰, 스마트 시계, 보청기 및 이어폰 등 고도로 소형화된 전자 제품에 이상적이며, 시스템 전력 수요를 증가시키는 여러가지 다양한 지능형 기능이 추가되는 추세를 지원한다. 이 제품들의 RDS(on)은 경쟁 디바이스들보다 최대 25% 뛰어나기 때문에 에너지 손실을 최소화하고 부하 스위칭 및 배터리 관리 효율성을 높여준다. 뛰어난 성능은 자체 발열을 줄여 웨어러블 장치에서 사용자의 편리성을 향상시킨다.- 아쿠아 시큐리티, 100만 달러 규모의 ‘클라우드 네이티브 보호 보증’ 프로그램 실시이 프로그램은 ‘클라우드 네이티브 애플리케이션 보호 플랫폼(CNAPP)’인 ‘아쿠아 플랫폼(Aqua Platform)’을 완전히 구축한 모든 고객에게 무상으로 제공되며, 이 플랫폼을 뚫고 공격을 받은 고객에게 최대 100만 달러를 지급한다. 이는 아쿠아 플랫폼(Aqua Platform)의 방어 능력과 기술력에 대한 자신감을 기반으로 도입된 것으로 업계 유일의 보증 프로그램이다.
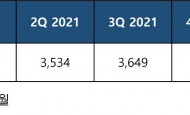 2022년 2분기 전 세계 실리콘 웨이퍼 출하량 신기록 달성SEMI는 2022년 2분기의 글로벌 실리콘 웨이퍼 출하량이 직전 분기 대비 1% 상승한 37억 400만 제곱 인치로 다시 한번 역대 최고치를 기록했다고 밝혔다. 이번에 발표된 수치는 전년 동기인 35억 3400만 제곱 인치 대비 5% 성장한 수치이다.
2022년 2분기 전 세계 실리콘 웨이퍼 출하량 신기록 달성SEMI는 2022년 2분기의 글로벌 실리콘 웨이퍼 출하량이 직전 분기 대비 1% 상승한 37억 400만 제곱 인치로 다시 한번 역대 최고치를 기록했다고 밝혔다. 이번에 발표된 수치는 전년 동기인 35억 3400만 제곱 인치 대비 5% 성장한 수치이다. KT그룹, 2022년 상반기 혁신 성과 및 사례 공유행사는 ‘DIGICO Ground! 더 멀리, 더 높이, 더 빨리’를 테마로 구성됐으며, 디지털 플랫폼 기업으로의 혁신을 위해 원팀(One-Team)으로 함께 달려 온 KT그룹 구성원들의 사례를 공유하고 격려하는 자리로 마련됐다. 결과뿐만 아니라 과정이 우수한 과제를 포함해 2022년 KT의 경영방향인 ‘안정’, ‘고객’, ‘성장’ 분야에서 괄목할 성과를 낸 총 11개의 우수 사례가 선정돼 발표 무대에 올랐다.
KT그룹, 2022년 상반기 혁신 성과 및 사례 공유행사는 ‘DIGICO Ground! 더 멀리, 더 높이, 더 빨리’를 테마로 구성됐으며, 디지털 플랫폼 기업으로의 혁신을 위해 원팀(One-Team)으로 함께 달려 온 KT그룹 구성원들의 사례를 공유하고 격려하는 자리로 마련됐다. 결과뿐만 아니라 과정이 우수한 과제를 포함해 2022년 KT의 경영방향인 ‘안정’, ‘고객’, ‘성장’ 분야에서 괄목할 성과를 낸 총 11개의 우수 사례가 선정돼 발표 무대에 올랐다. 로데슈바르즈, On-Wafer 디바이스의 특성화를 지원하는 테스트 솔루션 출시로데슈바르즈의 고성능 벡터 네트워크 분석기인 R&S ZNA와 폼팩터(FormFactor)의 업계 선도적인 엔지니어링 프로브 시스템을 결합한 On-Wafer RF 퍼포먼스 특성화 솔루션은 반도체 제조사의 개발 단계 및 제품의 품질검증 과정, 그리고 생산 단계에서 안정적이고 재연 가능한 On-Wafer 디바이스 특성화 수행을 완벽하게 지원한다.
로데슈바르즈, On-Wafer 디바이스의 특성화를 지원하는 테스트 솔루션 출시로데슈바르즈의 고성능 벡터 네트워크 분석기인 R&S ZNA와 폼팩터(FormFactor)의 업계 선도적인 엔지니어링 프로브 시스템을 결합한 On-Wafer RF 퍼포먼스 특성화 솔루션은 반도체 제조사의 개발 단계 및 제품의 품질검증 과정, 그리고 생산 단계에서 안정적이고 재연 가능한 On-Wafer 디바이스 특성화 수행을 완벽하게 지원한다.- 큐브리드, 오픈소스 DBMS CUBRID 11.2 버전 출시새롭게 출시된 CUBRID 11.2는 데이터베이스 링크 및 서플리멘탈 로깅(supplemental logging)을 통해 동기종과 이기종 DB 간 확장성을 강화했다. 변경된 데이터 추적이 가능한 서플리멘탈 로깅 기능으로 트랜잭션별 변경된 데이터의 원복 질의를 추출할 수 있는 플래시백(flashback)이 가능해졌다.
 넥스페리아의 초저 정전 용량 ESD 보호 다이오드, 자동차 데이터 인터페이스를 보호해넥스페리아 정전기 방전(ESD) 전압 클램핑 다이오드는 자동차 서브시스템의 데이터 인터페이스가 손상되지 않도록 보호하는 중요한 기능을 수행한다. 그러면서도 데이터 신호 무결성을 저하시키거나 시스템의 전자기 호환성(EMC) 성능에 부정적인 영향을 미치지 않는다. 모든 제품들은 전기적 성능과 신호 무결성을 향상시켜주는 무연 패키지로 제공된다.
넥스페리아의 초저 정전 용량 ESD 보호 다이오드, 자동차 데이터 인터페이스를 보호해넥스페리아 정전기 방전(ESD) 전압 클램핑 다이오드는 자동차 서브시스템의 데이터 인터페이스가 손상되지 않도록 보호하는 중요한 기능을 수행한다. 그러면서도 데이터 신호 무결성을 저하시키거나 시스템의 전자기 호환성(EMC) 성능에 부정적인 영향을 미치지 않는다. 모든 제품들은 전기적 성능과 신호 무결성을 향상시켜주는 무연 패키지로 제공된다. 엔비디아 인셉션 회원 루닛, 코스닥 신규 상장루닛은 지난해 두 가지 AI 소프트웨어에 대한 FDA 승인을 받았다. 하나는 유방촬영술에서 유방암 징후를 분석하고, 다른 하나는 흉부 엑스레이에서 살펴봐야 하는 주요 질환을 검출한다. 이 두 가지를 비롯해 암 조직 샘플의 종양 미세 환경을 분석하는 세 번째 모델까지 유럽에서 CE 인증을 획득했다.
엔비디아 인셉션 회원 루닛, 코스닥 신규 상장루닛은 지난해 두 가지 AI 소프트웨어에 대한 FDA 승인을 받았다. 하나는 유방촬영술에서 유방암 징후를 분석하고, 다른 하나는 흉부 엑스레이에서 살펴봐야 하는 주요 질환을 검출한다. 이 두 가지를 비롯해 암 조직 샘플의 종양 미세 환경을 분석하는 세 번째 모델까지 유럽에서 CE 인증을 획득했다. 연합 학습 분산 트레이닝, 공유 모델을 통한 AI 우수성 향상IoT의 급속한 발전과 5G 네트워크의 보급으로 인해 수많은 단말 장치가 네트워크에 연결되어 방대한 양의 데이터를 생성하고 있다. 기존의 데이터 컴퓨팅 및 분석은 클라우드 컴퓨팅을 기반으로 합니다. 데이터 양이 급격히 증가함에 따라, 애플리케이션 단말에서 클라우드 컴퓨팅 센터로의 전송시 지연이나 데이터 유출이 발생할 수 있다.
연합 학습 분산 트레이닝, 공유 모델을 통한 AI 우수성 향상IoT의 급속한 발전과 5G 네트워크의 보급으로 인해 수많은 단말 장치가 네트워크에 연결되어 방대한 양의 데이터를 생성하고 있다. 기존의 데이터 컴퓨팅 및 분석은 클라우드 컴퓨팅을 기반으로 합니다. 데이터 양이 급격히 증가함에 따라, 애플리케이션 단말에서 클라우드 컴퓨팅 센터로의 전송시 지연이나 데이터 유출이 발생할 수 있다.
 ams OSRAM과 도미넌트 옵토 테크놀로지스, 지능형 RGB LED로 스마트 자동차 실내 조명 구현
ams OSRAM과 도미넌트 옵토 테크놀로지스, 지능형 RGB LED로 스마트 자동차 실내 조명 구현 원프레딕트, 산업 AI 설비관리 솔루션으로 국제전기전력전시회 참가
원프레딕트, 산업 AI 설비관리 솔루션으로 국제전기전력전시회 참가 에이디링크, 인텔 Amston-Lake 기반 모듈 출시
에이디링크, 인텔 Amston-Lake 기반 모듈 출시 자이스 코리아, 제약바이오 연구 혁신을 지원하는 최신 고품질 이미징 기술 공개
자이스 코리아, 제약바이오 연구 혁신을 지원하는 최신 고품질 이미징 기술 공개 KT, K-UAM 실증서 세계 최초 UAM 통합운용체계 검증
KT, K-UAM 실증서 세계 최초 UAM 통합운용체계 검증
- 마우저, 산업 및 웨어러블 기기를 위해 BLE 5.2 지원하는 아나로그디바이스의 마이크로컨트롤러 공급
- 제조업 98% 혁신과 시장 출시의 가장 큰 어려움으로 데이터 문제 지적
- 큐브리드, 오픈소스 DB관리 도구 디비버(DBeaver) 연동 강화
- 인섹시큐리티, 다수 모바일 기기 데이터 동시 추출 솔루션 ‘마그넷 그레이키 패스트트랙' 출시
- 델 테크놀로지스, 제조 엣지 환경 지원하는 포트폴리오 및 에코시스템 강화
- 페펄앤드푹스, 최대 60m의 측정 거리를 제공하는 소형 거리 센서 출시
그래픽 / 영상
 결정론, 새로운 이더넷 애플리케이션을 열다
결정론, 새로운 이더넷 애플리케이션을 열다 AMD, 새로운 2세대 버설 적응형 SoC로 AI 기반 임베디드 시스템의 종단간 가속 지원
AMD, 새로운 2세대 버설 적응형 SoC로 AI 기반 임베디드 시스템의 종단간 가속 지원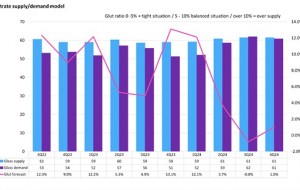 2024년, 디스플레이 글래스 산업 공급부족 우려
2024년, 디스플레이 글래스 산업 공급부족 우려
많이 본 뉴스
 로지텍, 하이브리드 워크플레이스를 위한 ‘로지텍 오픈 오피스 데이’ 성료
로지텍, 하이브리드 워크플레이스를 위한 ‘로지텍 오픈 오피스 데이’ 성료 로데슈바르즈와 슬라롬, 5G 기반 증강현실 애니메이션 아바타 통화 실현
로데슈바르즈와 슬라롬, 5G 기반 증강현실 애니메이션 아바타 통화 실현 지멘스 Simcenter 솔루션, 이모터스의 e-드라이브 소음진동 테스트에 채택
지멘스 Simcenter 솔루션, 이모터스의 e-드라이브 소음진동 테스트에 채택 다쏘시스템, 2024 독일 하노버 산업박람회에서 버추얼 트윈 혁신 선보인다
다쏘시스템, 2024 독일 하노버 산업박람회에서 버추얼 트윈 혁신 선보인다 로지텍, 플래그십 무선 게이밍 헤드셋 ‘A50 X’ 출시
로지텍, 플래그십 무선 게이밍 헤드셋 ‘A50 X’ 출시 어플라이드 머티어리얼즈, 2024년도 인텔 협력사 다양성 부문 ‘EPIC 우수 협력사 어워드’ 수상
어플라이드 머티어리얼즈, 2024년도 인텔 협력사 다양성 부문 ‘EPIC 우수 협력사 어워드’ 수상 ST, 향상된 효율과 전력밀도의 새로운 100V 트렌치 쇼트키 정류기 다이오드 제품군 공개
ST, 향상된 효율과 전력밀도의 새로운 100V 트렌치 쇼트키 정류기 다이오드 제품군 공개 로데슈바르즈, 새로운 블루투스 채널 사운딩 신호 측정 솔루션 최초 공개
로데슈바르즈, 새로운 블루투스 채널 사운딩 신호 측정 솔루션 최초 공개 엔비디아, AI로 무선 통신 발전시킬 6G 리서치 클라우드 플랫폼 공개
엔비디아, AI로 무선 통신 발전시킬 6G 리서치 클라우드 플랫폼 공개 마이크로칩, Qi v2.0 무선 충전 표준 준수 dsPIC33 기반 레퍼런스 디자인 출시
마이크로칩, Qi v2.0 무선 충전 표준 준수 dsPIC33 기반 레퍼런스 디자인 출시