
엔비디아(www.nvidia.co.kr, CEO 젠슨 황)가 딥 러닝 추론 가속화 솔루션 적용 노하우를 소개하는 ‘엔비디아 AI 개발자 밋업’을 온라인으로 진행한다고 밝혔다.
엔비디아 AI 개발자 밋업 행사 개요
엔비디아 AI 개발자 밋업 – 텐서 RT(TensorRT)/트리톤 추론 서버(Triton Inference Server)는 4월 21일 목요일 오후 2시부터 4시까지 온라인으로 진행된다. 이번 밋업에서는 쉽고 빠른 딥 러닝 추론 가속화 솔루션 적용 노하우를 소개한다.
밋업을 통해 엔비디아는 자사 GPU로 학습한 딥 러닝 모델을 실제 추론을 위해 양산에 적용할 때 고려해야 할 점들을 소개한다. 함수(.predict()와 .forward())를 활용해 간단하게 적용하는 방법부터 인프라에 맞는 고유한 요구 사항을 바탕으로 추론 적용과 최적화에 이르는 엔비디아만의 해결 방법을 제안한다.
밋업에서는 엔비디아 추론 워크플로우를 단계별로 살펴본다. 딥 러닝 모델 최적화를 위한 텐서 RT와 확장 가능하고 유연한 추론 서빙을 위한 엔비디아 트리톤 추론 서버에 대한 최신 업데이트 사항 및 핸즈온 데모 세션을 통해 쉽고 빠른 딥 러닝 애플리케이션 프로덕션 통합 방법도 배울 수 있다. 발표는 엔비디아 솔루션 아키텍트 이진호 대리와 디벨로퍼 릴레이션스(Developer Relations) 매니저 서완석 상무가 맡는다.
더불어, 엔비디아 전문가들과 함께하는 질의응답 세션과 참가자들을 위한 이벤트도 진행된다. 온라인으로 진행되는 본 행사는 링크를 통해 등록할 수 있다. 참가자 전원에게 별도의 온라인 참가 링크가 이메일과 문자로 안내된다.
주요 플랫폼 및 SDK 소개
- 텐서 RT: AI 추론이 최신 애플리케이션 트렌드를 주도하면서 빠르고 쉬운 추론 구축에 대한 수요도 높아졌다. 하지만 추론은 실시간, 경쟁적인 제약 조건, 빠른 업데이트를 요구하기 때문에 복잡하다. 모든 프레임워크에서 각 타깃 플랫폼에 최적화를 도와주는 엔비디아 텐서 RT는 컴파일러와 런타임으로 지연 시간이 중요한 애플리케이션의 처리량(throughput)을 최대화하며 CNN, RNN과 트랜스포머를 포함한 모든 네트워크를 최적화한다. 또한 텐서 RT는 세계에서 가장 발전한 추론 SDK로 25,000개 이상의 고객이 클라우드에서 엣지에 이르기까지 다양한 산업에 걸쳐 활용하고 있다.
- 트리톤 추론 서버: 엔비디아 트리톤 추론 서버(트리톤)는 성능을 극대화하고 규모에 맞게 모델 배포를 단순화하는 오픈 소스 추론 서비스 소프트웨어이다. 추론 서빙(inference serving)은 프로덕션 활동에 해당하며 여러 생태계의 소프트웨어 및 툴과의 통합이 필요할 수 있다. 트리톤은 클라우드, 데이터센터, 엣지의 GPU/CPU 기반 인프라에서 사용자 지정 쿠다(CUDA)와 파이썬(Python) 백엔드를 사용해 텐서 RT, 텐서플로우(TensorFlow), 오픈 뉴럴 네트워크 익스체인지(ONNX), 파이토치(PyTorch) 등을 비롯한 다중 프레임워크를 지원한다. 트리톤은 컴퓨터 비전, 자연어 처리, 금융 서비스 등을 위한 애플리케이션 일체의 프로덕션에서 대⋅소규모 고객사가 모두 사용할 수 있는 모델들을 제공한다.
저작권©올포칩 미디어. 무단전재 및 재배포를 금지합니다.
 기가몬, 셰인 버클리(Shane Buckley) 사장 겸 CEO 임명버클리 CEO는 기가몬이 복잡한 컴퓨팅 운영 환경에 대한 보다 심층적인 가시성 확보를 위해 네트워크 분석과 보안 대응 정보를 제공하는 ‘딥 옵저버빌리티(deep observability)’ 분야의 마켓 대표 기업으로서 자리매김하는데 주력할 것이다. 기가몬은 실행 가능한 네트워크단의 고급 정보 인텔리전스를 활용하여 고객들이 클라우드, 보안 및 가시성 툴의 성능을 극대화할 수 있는 딥 옵저버빌리티(Deep Observability) 파이프라인(경로)를 제공한다.
기가몬, 셰인 버클리(Shane Buckley) 사장 겸 CEO 임명버클리 CEO는 기가몬이 복잡한 컴퓨팅 운영 환경에 대한 보다 심층적인 가시성 확보를 위해 네트워크 분석과 보안 대응 정보를 제공하는 ‘딥 옵저버빌리티(deep observability)’ 분야의 마켓 대표 기업으로서 자리매김하는데 주력할 것이다. 기가몬은 실행 가능한 네트워크단의 고급 정보 인텔리전스를 활용하여 고객들이 클라우드, 보안 및 가시성 툴의 성능을 극대화할 수 있는 딥 옵저버빌리티(Deep Observability) 파이프라인(경로)를 제공한다.- 맨디언트, 글로벌 사이버 위협에 대한 인사이트 공개맨디언트의 연례 보고서인 M-트렌드는 한 해간 전 세계적으로 큰 영향을 미친 사이버 공격에 대한 맨디언트의 조사와 복구 및 대응 경험을 기반으로 글로벌 사이버 위협에 대한 데이터와 인사이트를 제공한다. 2022 M-트렌드는 위협 탐지 및 대응에서 조직들의 상당한 발전이 있었지만, 공격 표적이 된 조직의 환경에 침투하기 위한 지속적인 공격 기술 혁신 또한 관찰됐다고 보고했다.
- 인텔 그래픽, 외장 GPU로 확장최근 출시된 노트북용 인텔 아크(Intel Arc) 외장 그래픽 제품은 이러한 기대에 부응한 첫 단계로 인텔의 오랜 그래픽 분야 역사의 중요한 진일보이다. 데스크톱용 인텔 아크는 연내 출시할 예정이다. 시장에 새로운 플레이어로 경쟁력 있는 제품을 제공하기 위해서는 뛰어난 기능과 성능을 제공하는 것은 물론 다양한 게임과 애플리케이션을 지원해야 한다. 나왈레는 “인텔의 아키텍처는 항상 소프트웨어 우선 접근 방식을 취해왔다”고 말했다.
- 다쏘시스템, 지능형 모빌리티를 위한 소프트웨어 리퍼블리크 스타트업 인큐베이터 프로그램 진행소프트웨어 리퍼블리크는 다쏘시스템, 아토스, 오렌지, 르노그룹, ST마이크로일렉트로닉스, 탈레스가 스마트 모빌리티 혁신을 위해 공동 설립한 그룹이다. 프로그램 개회식은 프랑스 파리에 위치한 스타트업 엑셀러레이터 네트워크인 빌리지바이 CA (Village by CA)에서 진행되었으며, 소프트웨어 리퍼블리크의 창립 멤버와 인큐베이터 프로그램에 선정된 스타트업 기업들이 참가했다.
 테스트웍스, 국제인공지능대전(AI EXPO KOREA 2022) 참가테스트웍스 부스에서 가장 관심을 받았던 공간은 라이다(LiDAR) 실시간 3D 데이터 수집 데모로, 3D 데이터 가공까지 가능하다는 점에서 관객들의 큰 주목을 받았다. 또한 테스트웍스의 자동화 가공 관리 솔루션인 ‘블랙올리브(blackolive)’로 멀티센서 동선 추적 및 수어 영상 데이터를 자동화 가공하는 방법을 소개하여 큰 관심을 모았다.
테스트웍스, 국제인공지능대전(AI EXPO KOREA 2022) 참가테스트웍스 부스에서 가장 관심을 받았던 공간은 라이다(LiDAR) 실시간 3D 데이터 수집 데모로, 3D 데이터 가공까지 가능하다는 점에서 관객들의 큰 주목을 받았다. 또한 테스트웍스의 자동화 가공 관리 솔루션인 ‘블랙올리브(blackolive)’로 멀티센서 동선 추적 및 수어 영상 데이터를 자동화 가공하는 방법을 소개하여 큰 관심을 모았다. 엔비디아, 로보틱스 기술 소개하는 온라인 젯슨 개발자 밋업 진행해당 밋업에서는 로보틱스의 미래를 선도할 강력한 드라이버를 선보인다. 엔비디아는 GTC 2022를 통해 세계에서 가장 강력하고 콤팩트한 AI 슈퍼 컴퓨터 ‘엔비디아 젯슨 AGX 오린(Orin)’ 개발자 키트를 출시하면서 첨단 로보틱스, 자율 기계, 차세대 임베디드와 엣지 컴퓨팅 산업 혁신을 이끌고 있다.
엔비디아, 로보틱스 기술 소개하는 온라인 젯슨 개발자 밋업 진행해당 밋업에서는 로보틱스의 미래를 선도할 강력한 드라이버를 선보인다. 엔비디아는 GTC 2022를 통해 세계에서 가장 강력하고 콤팩트한 AI 슈퍼 컴퓨터 ‘엔비디아 젯슨 AGX 오린(Orin)’ 개발자 키트를 출시하면서 첨단 로보틱스, 자율 기계, 차세대 임베디드와 엣지 컴퓨팅 산업 혁신을 이끌고 있다.- PCI-SIG, 텔레다인르크로이 PCI Express 컴플라이언스 솔루션 승인프로세서와 주변장치 간의 빠르고 효율적인 전송을 구동하는 데 필요한 시리얼 확장 버스 및 관련 구성 요소의 정의를 담당하는 PCI-SIG가 텔레다인르크로이를 PCI-SIG 컴플라이언스 워크숍에서 공식 PCI Express 5.0 링크 및 트랜잭션 레이어 컴플라이언스 테스트를 위한 솔루션 공급업체로 승인했다고 발표했다.
 텔레다인르크로이, PCIe 컴플라이언스 테스트 속도 향상, 추가 전기 및 프로토콜 테스트 장비 제공텔레다인르크로이는 PCIe 전기 및 프로토콜 컴플라이언스를 위한 추가 컴플라이언스 스위트 테스트 기기를 PCI-SIG에 제공했다. 장비에는 36GHz LabMaster 오실로스코프, Summit Z58 프로토콜 실행 장치/실천 장치, PXP-500A PCIe 테스트 플랫폼 및 WavePulser 40iX 고속 상호 연결 분석기가 포함되었다.
텔레다인르크로이, PCIe 컴플라이언스 테스트 속도 향상, 추가 전기 및 프로토콜 테스트 장비 제공텔레다인르크로이는 PCIe 전기 및 프로토콜 컴플라이언스를 위한 추가 컴플라이언스 스위트 테스트 기기를 PCI-SIG에 제공했다. 장비에는 36GHz LabMaster 오실로스코프, Summit Z58 프로토콜 실행 장치/실천 장치, PXP-500A PCIe 테스트 플랫폼 및 WavePulser 40iX 고속 상호 연결 분석기가 포함되었다. 한국레노버, ‘씽크스테이션 P620’ 신제품 출시새롭게 출시된 씽크스테이션 P620은 AMD 라이젠 스레드리퍼 프로 5000WX 시리즈를 장착한 업계 유일의 최상급 전문가용 워크스테이션으로 전세대 대비 25% 향상된 성능을 제공한다. 하이브리드 작업 환경과 함께 복잡해진 워크플로우는 최고의 성능을 제공하는 유연한 워크스테이션을 필요로 한다.
한국레노버, ‘씽크스테이션 P620’ 신제품 출시새롭게 출시된 씽크스테이션 P620은 AMD 라이젠 스레드리퍼 프로 5000WX 시리즈를 장착한 업계 유일의 최상급 전문가용 워크스테이션으로 전세대 대비 25% 향상된 성능을 제공한다. 하이브리드 작업 환경과 함께 복잡해진 워크플로우는 최고의 성능을 제공하는 유연한 워크스테이션을 필요로 한다. 마우저, ADI의 CN0534 LNA 수신기 레퍼런스 설계 장치 공급마우저에서 제공하는 아나로그디바이스(ADI) CN0534 LNA 수신기 레퍼런스 설계 장치는 5.8GHz의 중심 주파수에서 작동하도록 최적화된 +23dB 이득의 고성능 RF 수신기 시스템이다. 입력은 필터링되지 않고 2dB의 잡음 지수를 유지하는 반면, 출력의 대역통과 필터는 대역 외 간섭을 감쇠한다.
마우저, ADI의 CN0534 LNA 수신기 레퍼런스 설계 장치 공급마우저에서 제공하는 아나로그디바이스(ADI) CN0534 LNA 수신기 레퍼런스 설계 장치는 5.8GHz의 중심 주파수에서 작동하도록 최적화된 +23dB 이득의 고성능 RF 수신기 시스템이다. 입력은 필터링되지 않고 2dB의 잡음 지수를 유지하는 반면, 출력의 대역통과 필터는 대역 외 간섭을 감쇠한다. KT, ‘로봇 자동화’ 디지털 업무혁신으로 “지난해 100억원 이상 비용절감”‘디지코(DIGICO)’를 표방하며 디지털 전환을 가속화하고 있는 KT는 지난 2020년부터 ‘언택트(Untact)’, ‘페이퍼리스(Paperless)’ 업무 시스템을 구현해 직원들이 더욱 자유롭고 편리하게 일할 수 있는 환경을 구축하고 있다. 그 일환으로 로봇프로세스자동화(RPA) 도구를 적극 도입해, 임직원들의 단순반복적 전산업무를 자동화하고 모바일로 간편하게 수행함으로써 업무 시간을 크게 줄였다.
KT, ‘로봇 자동화’ 디지털 업무혁신으로 “지난해 100억원 이상 비용절감”‘디지코(DIGICO)’를 표방하며 디지털 전환을 가속화하고 있는 KT는 지난 2020년부터 ‘언택트(Untact)’, ‘페이퍼리스(Paperless)’ 업무 시스템을 구현해 직원들이 더욱 자유롭고 편리하게 일할 수 있는 환경을 구축하고 있다. 그 일환으로 로봇프로세스자동화(RPA) 도구를 적극 도입해, 임직원들의 단순반복적 전산업무를 자동화하고 모바일로 간편하게 수행함으로써 업무 시간을 크게 줄였다. 오나인솔루션즈, ‘펩시’와 IBP 파트너십 체결펩시(PepsiCo)는 o9의 협업 계획 플랫폼을 기반으로 실시간 시나리오 계획을 수행하고 다양한 상업 및 공급망 시나리오를 평가할 수 있게 되었으며, 이를 통해 의사결정의 효율성을 높이고 더욱 완벽한 실행을 할 수 있게 되었다. o9의 입증된 기술을 통해 펩시(PepsiCo)는 기능간 계획 및 효율성, 최적화된 의사결정을 지원하는 분석 기반 협업 플랫폼을 활용할 수 있게 되었다
오나인솔루션즈, ‘펩시’와 IBP 파트너십 체결펩시(PepsiCo)는 o9의 협업 계획 플랫폼을 기반으로 실시간 시나리오 계획을 수행하고 다양한 상업 및 공급망 시나리오를 평가할 수 있게 되었으며, 이를 통해 의사결정의 효율성을 높이고 더욱 완벽한 실행을 할 수 있게 되었다. o9의 입증된 기술을 통해 펩시(PepsiCo)는 기능간 계획 및 효율성, 최적화된 의사결정을 지원하는 분석 기반 협업 플랫폼을 활용할 수 있게 되었다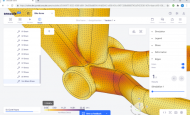 앤시스, 클라우드 시뮬레이션 기업 ‘온스케일’ 인수온스케일의 기술은 앤시스의 기존 클라우드 포트폴리오에 통합된다. 이를 통해 앤시스의 광범위한 시뮬레이션 기술에 대한 장치 독립적 액세스(모든 기기에서 접속 가능)를 위한 클라우드 네이티브 웹 기반 사용자 인터페이스(UI)를 제공할 수 있을 것으로 예상된다. 거래 조건은 공개되지 않았다. 이번 인수는 앤시스의 2022년 연결 재무제표에 큰 영향을 미치지 않을 것으로 예상된다.
앤시스, 클라우드 시뮬레이션 기업 ‘온스케일’ 인수온스케일의 기술은 앤시스의 기존 클라우드 포트폴리오에 통합된다. 이를 통해 앤시스의 광범위한 시뮬레이션 기술에 대한 장치 독립적 액세스(모든 기기에서 접속 가능)를 위한 클라우드 네이티브 웹 기반 사용자 인터페이스(UI)를 제공할 수 있을 것으로 예상된다. 거래 조건은 공개되지 않았다. 이번 인수는 앤시스의 2022년 연결 재무제표에 큰 영향을 미치지 않을 것으로 예상된다.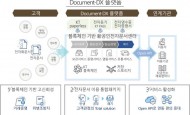 KT, 국내 최초 블록체인 기반 공인전자문서센터 지정인가 획득최근 ESG 경영 및 비대면 경제가 활성화로 인해 전자문서의 중요성이 확대 되고 있는 가운데, 공전센터는 디지털 전환을 위한 주요 서비스로 언급되고 있다. 공전센터는 전자문서의 효율적이고 안전한 보관과 내용의 미변경 등이 증명되며, 과기정통부 장관으로부터 지정 받은 법인 또는 국가기관을 칭한다.
KT, 국내 최초 블록체인 기반 공인전자문서센터 지정인가 획득최근 ESG 경영 및 비대면 경제가 활성화로 인해 전자문서의 중요성이 확대 되고 있는 가운데, 공전센터는 디지털 전환을 위한 주요 서비스로 언급되고 있다. 공전센터는 전자문서의 효율적이고 안전한 보관과 내용의 미변경 등이 증명되며, 과기정통부 장관으로부터 지정 받은 법인 또는 국가기관을 칭한다.
 ams OSRAM과 도미넌트 옵토 테크놀로지스, 지능형 RGB LED로 스마트 자동차 실내 조명 구현
ams OSRAM과 도미넌트 옵토 테크놀로지스, 지능형 RGB LED로 스마트 자동차 실내 조명 구현 원프레딕트, 산업 AI 설비관리 솔루션으로 국제전기전력전시회 참가
원프레딕트, 산업 AI 설비관리 솔루션으로 국제전기전력전시회 참가 에이디링크, 인텔 Amston-Lake 기반 모듈 출시
에이디링크, 인텔 Amston-Lake 기반 모듈 출시 자이스 코리아, 제약바이오 연구 혁신을 지원하는 최신 고품질 이미징 기술 공개
자이스 코리아, 제약바이오 연구 혁신을 지원하는 최신 고품질 이미징 기술 공개 KT, K-UAM 실증서 세계 최초 UAM 통합운용체계 검증
KT, K-UAM 실증서 세계 최초 UAM 통합운용체계 검증
- 마우저, 산업 및 웨어러블 기기를 위해 BLE 5.2 지원하는 아나로그디바이스의 마이크로컨트롤러 공급
- 제조업 98% 혁신과 시장 출시의 가장 큰 어려움으로 데이터 문제 지적
- 큐브리드, 오픈소스 DB관리 도구 디비버(DBeaver) 연동 강화
- 인섹시큐리티, 다수 모바일 기기 데이터 동시 추출 솔루션 ‘마그넷 그레이키 패스트트랙' 출시
- 델 테크놀로지스, 제조 엣지 환경 지원하는 포트폴리오 및 에코시스템 강화
- 페펄앤드푹스, 최대 60m의 측정 거리를 제공하는 소형 거리 센서 출시
그래픽 / 영상
 인터넷의 ‘필터 버블(Filter Bubble)’ 깨부수기
인터넷의 ‘필터 버블(Filter Bubble)’ 깨부수기 결정론, 새로운 이더넷 애플리케이션을 열다
결정론, 새로운 이더넷 애플리케이션을 열다 AMD, 새로운 2세대 버설 적응형 SoC로 AI 기반 임베디드 시스템의 종단간 가속 지원
AMD, 새로운 2세대 버설 적응형 SoC로 AI 기반 임베디드 시스템의 종단간 가속 지원
많이 본 뉴스
 코닝 반 홀(Vaughn Hall) 한국 총괄사장, 코닝의 한국 지역 법인 통합 운영
코닝 반 홀(Vaughn Hall) 한국 총괄사장, 코닝의 한국 지역 법인 통합 운영 로데슈바르즈, 최대 50GHz까지 VCO 측정 및 위상 노이즈 분석을 지원하는 R&S FSPN50 출시
로데슈바르즈, 최대 50GHz까지 VCO 측정 및 위상 노이즈 분석을 지원하는 R&S FSPN50 출시 AMD 적응형 컴퓨팅 기술, 소니의 자동차용 라이다 레퍼런스 디자인 지원
AMD 적응형 컴퓨팅 기술, 소니의 자동차용 라이다 레퍼런스 디자인 지원 TI, 임베디드 월드2024에서 스마트하고 지속 가능한 미래를 위한 기술 소개
TI, 임베디드 월드2024에서 스마트하고 지속 가능한 미래를 위한 기술 소개 IMDT, AI 기반 비전 애플리케이션에 최적화된 새로운 SOM 및 SBC 출시
IMDT, AI 기반 비전 애플리케이션에 최적화된 새로운 SOM 및 SBC 출시 로데슈바르즈, 새로운 블루투스 채널 사운딩 신호 측정 솔루션 최초 공개
로데슈바르즈, 새로운 블루투스 채널 사운딩 신호 측정 솔루션 최초 공개 라이트닝 모터사이클, 바이코와 함께 전기 오토바이의 최고 지면 속도 신기록
라이트닝 모터사이클, 바이코와 함께 전기 오토바이의 최고 지면 속도 신기록 이튼, 데이터 센터 사업의 연속성 보장하는 대용량 UPS ‘9395XR’ 국내 출시
이튼, 데이터 센터 사업의 연속성 보장하는 대용량 UPS ‘9395XR’ 국내 출시 인텔, 엔터프라이즈용 AI PC를 위한 새로운 vPro 플랫폼 확대
인텔, 엔터프라이즈용 AI PC를 위한 새로운 vPro 플랫폼 확대 데이터브릭스, 범용 대형언어모델 ‘DBRX’로 효율적인 오픈소스 모델의 새로운 기준 제시
데이터브릭스, 범용 대형언어모델 ‘DBRX’로 효율적인 오픈소스 모델의 새로운 기준 제시