
엔비디아(www.nvidia.co.kr, CEO 젠슨 황)는 차세대 AI 데이터 센터를 지원하기 위해 이전 제품보다 성능이 크게 향상된 차세대 가속 컴퓨팅 플랫폼 엔비디아 호퍼(NVIDIA Hopper) 아키텍처를 발표했다. 미국의 선구적인 컴퓨터 과학자 그레이스 호퍼(Grace Hopper)의 이름을 딴 이 새로운 아키텍처는 2년 전에 출시된 엔비디아 암페어(NVIDIA Ampere) 아키텍처를 계승한다.
또한 800억 개의 트랜지스터를 탑재한 최초의 호퍼 기반의 GPU인 엔비디아 H100도 발표했다. 세계에서 가장 크고 강력한 액셀러레이터인 H100은 혁신적인 트랜스포머 엔진, 확장성이 뛰어난 엔비디아 NVLink 인터커넥트 등의 획기적인 기능을 갖추고 있어 대형 AI 언어 모델, 딥 추천 시스템, 유전체학 및 복잡한 디지털 트윈을 지원한다.
젠슨 황(Jensen Huang) 엔비디아 설립자이자 CEO는 "데이터 센터는 인공지능 공장이 되고 있으며 엔비디아 H100은 기업들이 AI가 주도하는 비즈니스를 가속화하기 위해 사용하는 세계 AI 인프라의 엔진"이라고 말했다.
H100의 결합된 기술 혁신은 엔비디아의 AI 추론 및 훈련 리더십을 확장하여 대규모 AI 모델을 사용하여 실시간 몰입형 애플리케이션을 가능하게 한다. H100은 세계에서 가장 강력한 단일 트랜스포머 언어 모델인 Megatron 530B를 사용하여 실시간 대화 AI에 필요한 1초 미만의 지연 시간을 충족하면서 이전 세대보다 처리량을 30배까지 향상시킨다. 또한 H100을 사용하면 3,950억 개의 매개변수를 사용하여 전문가 혼합과 같은 대규모 모델을 최대 9배 빠르게 교육할 수 있어 교육 시간을 몇 주에서 몇 일로 단축할 수 있다.
엔비디아의 가속화된 컴퓨팅 요구에 맞게 설계된 최첨단 TSMC 4N 프로세스를 사용하여 800억 개의 트랜지스터로 구축된 H100은 AI, HPC, 메모리 대역폭, 상호 연결 및 통신을 가속화하며 초당 5TB에 가까운 외부 연결이 가능하다. H100은 PCIe Gen5를 지원하고 HBM3를 사용하는 최초의 GPU로 3TB/s의 메모리 대역폭을 실현한다. 20대의 H100 GPU는 전 세계 인터넷 트래픽과 동등한 성능을 유지할 수 있기 때문에 고객들은 데이터에 대한 추론을 실행하는 고급 추천 시스템 및 대규모 언어 모델을 실시간으로 제공할 수 있다.
H100은 세계 최초로 기밀 컴퓨팅 기능을 갖춘 가속기로, AI 모델과 고객 데이터가 처리되는 동안 이를 보호한다. 또한 고객은 개인 정보 보호에 민감한 산업 및 공유 클라우드 인프라에 대한 페더레이티드 러닝에도 기밀 컴퓨팅을 적용할 수 있다.
새로운 DPX 명령은 경로 최적화 및 유전체학 등 광범위한 알고리즘에 사용되는 동적 프로그래밍을 이전 세대 CPU 대비 40배, GPU 대비 7배 가속화한다. 여기에는 동적 창고 환경에서 자동화 로봇 집단을 위해 최적의 경로를 찾기 위한 Floyd-Warshall 알고리즘과 DNA 및 단백질 분류 및 폴딩을 위한 시퀀스 정렬에 사용되는 스미스-워터맨(Smith-Waterman) 알고리즘이 포함된다.
호퍼는 H100 기반 인스턴스를 제공할 예정인 주요 클라우드 서비스 공급자 알리바바 클라우드, AWS, 바이두 AI 클라우드, 구글 클라우드, 마이크로소프트 애저(Azure), 오라클 클라우드 및 텐센트 클라우드로부터 광범위한 지원을 받아왔다.
저작권©올포칩 미디어. 무단전재 및 재배포를 금지합니다.
 지멘스, 시에라 스페이스의 우주 탐사 혁신 지원시에라 스페이스가 차세대 디지털 엔지니어링 프로그램의 기반으로 지멘스의 엑셀러레이터(Xcelerator) 소프트웨어와 서비스 포트폴리오를 채택한다고 발표했다. 이를 통해 미래의 우주 운송, 상업용 우주 목적지 및 인프라 개발 목표 실현을 지원하고, 역동적이고 성장하며 접근 가능한 상업용 우주 경제를 구축할 수 있는 기술을 창출할 수 있을 것으로 예상된다.
지멘스, 시에라 스페이스의 우주 탐사 혁신 지원시에라 스페이스가 차세대 디지털 엔지니어링 프로그램의 기반으로 지멘스의 엑셀러레이터(Xcelerator) 소프트웨어와 서비스 포트폴리오를 채택한다고 발표했다. 이를 통해 미래의 우주 운송, 상업용 우주 목적지 및 인프라 개발 목표 실현을 지원하고, 역동적이고 성장하며 접근 가능한 상업용 우주 경제를 구축할 수 있는 기술을 창출할 수 있을 것으로 예상된다. ‘마이크로소프트 에브리웨어 2022’ 개최한국마이크로소프트는 온라인 포럼 ‘마이크로소프트 에브리웨어 2022’를 열고 한국은 물론 전 세계 기업들이 주목하는 4가지 주제들을 시리즈로 발표한다. 각 시리즈에서는 앞서 이를 성공적으로 적용한 주요 기업들의 전략과 사례가 소개되며, 이를 통해 도출된 비즈니스 인사이트와 방향성이 제시될 예정이다.
‘마이크로소프트 에브리웨어 2022’ 개최한국마이크로소프트는 온라인 포럼 ‘마이크로소프트 에브리웨어 2022’를 열고 한국은 물론 전 세계 기업들이 주목하는 4가지 주제들을 시리즈로 발표한다. 각 시리즈에서는 앞서 이를 성공적으로 적용한 주요 기업들의 전략과 사례가 소개되며, 이를 통해 도출된 비즈니스 인사이트와 방향성이 제시될 예정이다. 마이크로소프트, ‘사이버 보안 스킬 캠페인’ 한국 포함 23개국 확대전 세계적으로 사이버 공격 규모가 기록을 갱신하고 있다. 이 같은 현상으로 공급망 중단, 랜섬웨어 공격 등 범죄의 양상이 다양해지면서 정부와 기업을 아우르는 모두에게 큰 위협이 되고 있다. 특히 전문 기술을 갖춘 인력 부족과 기술 격차로 인해 한계에 부딪히며 난항을 겪는 현상이 심화되고 있다.
마이크로소프트, ‘사이버 보안 스킬 캠페인’ 한국 포함 23개국 확대전 세계적으로 사이버 공격 규모가 기록을 갱신하고 있다. 이 같은 현상으로 공급망 중단, 랜섬웨어 공격 등 범죄의 양상이 다양해지면서 정부와 기업을 아우르는 모두에게 큰 위협이 되고 있다. 특히 전문 기술을 갖춘 인력 부족과 기술 격차로 인해 한계에 부딪히며 난항을 겪는 현상이 심화되고 있다.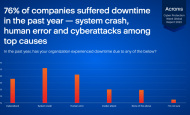 아크로니스, 연례 ‘사이버 보호 주간 글로벌 보고서 2022’ 발표아크로니스의 ‘사이버 보호 주간 글로벌 보고서 2022’는 22개국의 기업에 근무하는 6,200명 이상의 IT 사용자와 IT 관리자를 대상으로 설문 조사를 진행해 분석하였으며, 오늘날 사이버 보호 관행에 나타나는 가장 중요한 결점을 밝히고 이러한 결점이 나타나는 이유를 조사하여 안전하게 수정하는 방법에 대한 지침을 제공한다.
아크로니스, 연례 ‘사이버 보호 주간 글로벌 보고서 2022’ 발표아크로니스의 ‘사이버 보호 주간 글로벌 보고서 2022’는 22개국의 기업에 근무하는 6,200명 이상의 IT 사용자와 IT 관리자를 대상으로 설문 조사를 진행해 분석하였으며, 오늘날 사이버 보호 관행에 나타나는 가장 중요한 결점을 밝히고 이러한 결점이 나타나는 이유를 조사하여 안전하게 수정하는 방법에 대한 지침을 제공한다. 인텔, 노트북용 아크 A-시리즈 외장그래픽 제품군 출시공개한 제품군은 인텔 아크 A시리즈 그래픽 포트폴리오 최초의 외장 그래픽 처리장치(GPU)로 인텔은 연내 인텔 아크 A 시리즈를 노트북, 데스크톱 및 워크스테이션에 걸쳐 확장할 계획이다. 인텔은 이날 첫 인텔 아크 탑재 노트북, 인텔 아크 A시리즈 모바일 그래픽 제품군을 비롯해 전 세계 게이머 및 크리에이터에 고성능 그래픽 경험을 제공할 수 있는 하드웨어, 소프트웨어 및 서비스 등을 아우르는 아크 플랫폼을 선보였다.
인텔, 노트북용 아크 A-시리즈 외장그래픽 제품군 출시공개한 제품군은 인텔 아크 A시리즈 그래픽 포트폴리오 최초의 외장 그래픽 처리장치(GPU)로 인텔은 연내 인텔 아크 A 시리즈를 노트북, 데스크톱 및 워크스테이션에 걸쳐 확장할 계획이다. 인텔은 이날 첫 인텔 아크 탑재 노트북, 인텔 아크 A시리즈 모바일 그래픽 제품군을 비롯해 전 세계 게이머 및 크리에이터에 고성능 그래픽 경험을 제공할 수 있는 하드웨어, 소프트웨어 및 서비스 등을 아우르는 아크 플랫폼을 선보였다. 엔비디아, 최신 지포스 RTX 3090 Ti 공개엔비디아의 2세대 RTX 아키텍처인 암페어(Ampere)를 적용한 RTX 3090 Ti는 기록적인 10,752개의 쿠다(CUDA) 코어를 탑재했으며 78개의 레이 트레이싱 TFLOPs(테라플롭스), 40개의 섀이더(Shader) TFLOPs 및 320개의 텐서(Tensor) TFLOPs 성능을 제공한다. 또한 가장 빠른 속도를 자랑하는 21Gbps GDDR6X 메모리 24GB를 탑재했다.
엔비디아, 최신 지포스 RTX 3090 Ti 공개엔비디아의 2세대 RTX 아키텍처인 암페어(Ampere)를 적용한 RTX 3090 Ti는 기록적인 10,752개의 쿠다(CUDA) 코어를 탑재했으며 78개의 레이 트레이싱 TFLOPs(테라플롭스), 40개의 섀이더(Shader) TFLOPs 및 320개의 텐서(Tensor) TFLOPs 성능을 제공한다. 또한 가장 빠른 속도를 자랑하는 21Gbps GDDR6X 메모리 24GB를 탑재했다. 한국 시놀로지 연간 매출 40% 성장, 신제품 출시로 기업 데이터 관리 수요 충족시놀로지(Synology)는 기업 시장 진출로 2021년 한국 시장 연간 매출이 40% 성장했으며, 저장 및 네트워크, 모니터링 신제품 출시로 기업의 데이터 관리 수요에 적극 대응하며 시장 확산에 더욱 주력할 방침이라고 밝혔다. 시놀로지 글로벌 누적 출하량은 2021년 1천만 대를 돌파하면서 연간 매출 30% 이상 성장했다.
한국 시놀로지 연간 매출 40% 성장, 신제품 출시로 기업 데이터 관리 수요 충족시놀로지(Synology)는 기업 시장 진출로 2021년 한국 시장 연간 매출이 40% 성장했으며, 저장 및 네트워크, 모니터링 신제품 출시로 기업의 데이터 관리 수요에 적극 대응하며 시장 확산에 더욱 주력할 방침이라고 밝혔다. 시놀로지 글로벌 누적 출하량은 2021년 1천만 대를 돌파하면서 연간 매출 30% 이상 성장했다. 인텔, 세계에서 가장 빠른 데스크톱 프로세서 12세대 인텔 코어 i9-12900KS 출시인텔은 새로운 12세대 인텔 코어 i9-12900KS 프로세서를 통해 데스크톱 게임의 한계를 확장해나가고 있다 인텔의 12세대 고성능 하이브리드 아키텍처에 기반한 신규 프로세서는 사상 최초로 2개의 코어로 5.5GHz 클럭 스피드에 도달해 극한의 게이밍 성능을 달성할 수 있도록 지원한다.
인텔, 세계에서 가장 빠른 데스크톱 프로세서 12세대 인텔 코어 i9-12900KS 출시인텔은 새로운 12세대 인텔 코어 i9-12900KS 프로세서를 통해 데스크톱 게임의 한계를 확장해나가고 있다 인텔의 12세대 고성능 하이브리드 아키텍처에 기반한 신규 프로세서는 사상 최초로 2개의 코어로 5.5GHz 클럭 스피드에 도달해 극한의 게이밍 성능을 달성할 수 있도록 지원한다. 바이코, 2022 WCX에서 최고 전력 밀도의 차량 솔루션 발표자동차 산업이 전기 자동차 산업으로 빠르게 변화함에 따라 전력 시스템 설계 엔지니어는 훨씬 더 높은 전력 분배 네트워크 설계를 위해 노력하고 있다. EV는 기존 내연 기관 차량보다 최대 20배 더 많은 전력을 요구하고, 이는 전력 전자 장치의 증가에 비례하여 그 크기와 무게도 증가한다. 바이코의 전력 모듈을 통해 엔지니어는 EV, PHEV, HEV 및 BEV용 고밀도 전력 분배 네트워크를 구축할 수 있다.
바이코, 2022 WCX에서 최고 전력 밀도의 차량 솔루션 발표자동차 산업이 전기 자동차 산업으로 빠르게 변화함에 따라 전력 시스템 설계 엔지니어는 훨씬 더 높은 전력 분배 네트워크 설계를 위해 노력하고 있다. EV는 기존 내연 기관 차량보다 최대 20배 더 많은 전력을 요구하고, 이는 전력 전자 장치의 증가에 비례하여 그 크기와 무게도 증가한다. 바이코의 전력 모듈을 통해 엔지니어는 EV, PHEV, HEV 및 BEV용 고밀도 전력 분배 네트워크를 구축할 수 있다. ST, 공간 절감형 및 낮은 오프셋의 20MHz 연산 증폭기 출시ST의 고성능 5V 연산 증폭기 제품군에 새롭게 추가된 TSV772는 레일-투-레일(Rail-to-Rail) 입력 및 출력과 20MHz 게인 대역폭(GBW: Gain-Bandwidth)을 갖췄으며, 안정적 단위 이득을 제공한다. 13V/µs의 슬루율(Slew Rate)과 7nV/√Hz의 입력 노이즈 밀도, 4kV ESD 성능(HBM)도 갖춰 전반적으로 매우 뛰어난 성능을 제공한다.
ST, 공간 절감형 및 낮은 오프셋의 20MHz 연산 증폭기 출시ST의 고성능 5V 연산 증폭기 제품군에 새롭게 추가된 TSV772는 레일-투-레일(Rail-to-Rail) 입력 및 출력과 20MHz 게인 대역폭(GBW: Gain-Bandwidth)을 갖췄으며, 안정적 단위 이득을 제공한다. 13V/µs의 슬루율(Slew Rate)과 7nV/√Hz의 입력 노이즈 밀도, 4kV ESD 성능(HBM)도 갖춰 전반적으로 매우 뛰어난 성능을 제공한다. KT, 서울-부산 구간 양자암호통신 품질평가 시행KT는 이번 품질 평가에 독자 개발한 ‘양자암호 서비스 품질 파라미터(QoS Parameter)’를 활용한다. ‘양자암호 서비스 품질 파라미터’는 지난 2월 국제전기통신연합(ITU)이 세계 최초로 국제 표준 승인한 양자암호통신 품질 평가 기준이다. 이번에 품질 평가를 시행하는 서울-부산 구간은 약 490km으로, 대한민국 국토 내에 구축된 양자암호통신 설비 중 가장 길다. 대한민국 국토 대부분에 관련 서비스 제공이 가능한 수준이다.
KT, 서울-부산 구간 양자암호통신 품질평가 시행KT는 이번 품질 평가에 독자 개발한 ‘양자암호 서비스 품질 파라미터(QoS Parameter)’를 활용한다. ‘양자암호 서비스 품질 파라미터’는 지난 2월 국제전기통신연합(ITU)이 세계 최초로 국제 표준 승인한 양자암호통신 품질 평가 기준이다. 이번에 품질 평가를 시행하는 서울-부산 구간은 약 490km으로, 대한민국 국토 내에 구축된 양자암호통신 설비 중 가장 길다. 대한민국 국토 대부분에 관련 서비스 제공이 가능한 수준이다. KT, 삼성전자에 환경안전 강화 위한 드론 시스템 구축KT가 구축한 드론 시스템은 기업전용 LTE 무선 보안 네트워크에 기반을 두고 운영된다. 드론에 부착된 카메라로 촬영한 영상 등을 정보유출로부터 안전하게 보호할 수 있다. 특히 드론 시스템에는 비행 제어 자동화 기술, 화재 감지기, 시설물 온도감지기 등과도 연동돼 사업장 내의 환경안전의 세밀한 감시가 가능하다.
KT, 삼성전자에 환경안전 강화 위한 드론 시스템 구축KT가 구축한 드론 시스템은 기업전용 LTE 무선 보안 네트워크에 기반을 두고 운영된다. 드론에 부착된 카메라로 촬영한 영상 등을 정보유출로부터 안전하게 보호할 수 있다. 특히 드론 시스템에는 비행 제어 자동화 기술, 화재 감지기, 시설물 온도감지기 등과도 연동돼 사업장 내의 환경안전의 세밀한 감시가 가능하다. 엔비디아, 드라이브 오린 생산 착수 및 새로운 전기차 고객 발표엔비디아는 전 세계 자동차 제조업체의 연이은 디자인 수상을 계기로, 자동차 관련 파이프라인이 향후 6년 동안 110억 달러 이상으로 증가했다고 밝혔다. 현재 25개 이상의 차량 제조업체가 엔비디아 드라이브 오린 SoC(system-on-a-chip, 시스템 온 칩)를 채택했다. 이 업체들은 올해부터 중앙 집중형 AI 컴퓨팅 플랫폼에 기반한 소프트웨어 정의 차량을 선보일 예정이다.
엔비디아, 드라이브 오린 생산 착수 및 새로운 전기차 고객 발표엔비디아는 전 세계 자동차 제조업체의 연이은 디자인 수상을 계기로, 자동차 관련 파이프라인이 향후 6년 동안 110억 달러 이상으로 증가했다고 밝혔다. 현재 25개 이상의 차량 제조업체가 엔비디아 드라이브 오린 SoC(system-on-a-chip, 시스템 온 칩)를 채택했다. 이 업체들은 올해부터 중앙 집중형 AI 컴퓨팅 플랫폼에 기반한 소프트웨어 정의 차량을 선보일 예정이다. ST, 고효율 전력 설계 지원하는 50W GaN 컨버터 출시단일 스위치 토폴로지와 전류감지 및 보호 회로를 내장한 고집적 VIPerGaN50은 초소형 및 저비용의 5mm x 6mm 패키지로 제공된다. 고속의 통합 GaN 트랜지스터를 통해서는 작고 가벼운 플라이백 트랜스포머로 높은 스위칭 주파수를 지원한다. 외부 부품을 최소한도로 추가해 첨단 고효율 SMPS(Switched-Mode Power Supply)를 설계할 수 있다.
ST, 고효율 전력 설계 지원하는 50W GaN 컨버터 출시단일 스위치 토폴로지와 전류감지 및 보호 회로를 내장한 고집적 VIPerGaN50은 초소형 및 저비용의 5mm x 6mm 패키지로 제공된다. 고속의 통합 GaN 트랜지스터를 통해서는 작고 가벼운 플라이백 트랜스포머로 높은 스위칭 주파수를 지원한다. 외부 부품을 최소한도로 추가해 첨단 고효율 SMPS(Switched-Mode Power Supply)를 설계할 수 있다.
 인텔 파운드리, 고개구율 극자외선(High-NA EUV) 도입으로 칩 제조 분야 선도
인텔 파운드리, 고개구율 극자외선(High-NA EUV) 도입으로 칩 제조 분야 선도 NXP, 연간 기업 지속 가능성 보고서 - ESG 목표 달성 현황 공개
NXP, 연간 기업 지속 가능성 보고서 - ESG 목표 달성 현황 공개 로데슈바르즈, 획기적인 성능으로 무장한 R&S NGC100 파워 서플라이 제품군 신규 출시
로데슈바르즈, 획기적인 성능으로 무장한 R&S NGC100 파워 서플라이 제품군 신규 출시 IMDT와 Hailo가 합작하여 최고의 실시간 성능을 위한 엣지 AI 솔루션 출시
IMDT와 Hailo가 합작하여 최고의 실시간 성능을 위한 엣지 AI 솔루션 출시 콩가텍, 인텔 코어 i3 및 인텔 아톰 x7000RE 프로세서 탑재 SMARC 모듈 출시
콩가텍, 인텔 코어 i3 및 인텔 아톰 x7000RE 프로세서 탑재 SMARC 모듈 출시
- 인텔, 세계 최대규모 뉴로모픽 시스템 공개
- 마이크로칩, 항공기 전기화 전화를 간소화하는 통합 구동 파워 솔루션 출시
- 텔레다인르크로이, 광범위한 통신 기술 데이터를 원활하게 포착하는 프론트라인 X500e 출시
- TTTech Auto, 복잡한 소프트웨어 통합을 혁신할 차세대 스케줄러 ‘MotionWise Schedule’ 출시
- 아이스아이, 글로벌 SAR 리더십 확장을 위한 기업의 성장 펀딩 라운드 초과 달성
- 오나인솔루션즈, 생성형 AI 기술 적용해 ‘o9 Digital Brain’ 플랫폼 강화
그래픽 / 영상
 결정론, 새로운 이더넷 애플리케이션을 열다
결정론, 새로운 이더넷 애플리케이션을 열다 AMD, 새로운 2세대 버설 적응형 SoC로 AI 기반 임베디드 시스템의 종단간 가속 지원
AMD, 새로운 2세대 버설 적응형 SoC로 AI 기반 임베디드 시스템의 종단간 가속 지원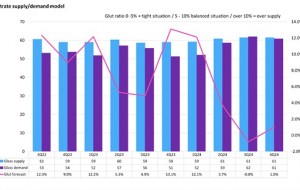 2024년, 디스플레이 글래스 산업 공급부족 우려
2024년, 디스플레이 글래스 산업 공급부족 우려
많이 본 뉴스
 시놀로지, DISS 2024 컨퍼런스에서 데이터 보안 관리 솔루션 선보여
시놀로지, DISS 2024 컨퍼런스에서 데이터 보안 관리 솔루션 선보여 엔비디아, cuPQC 소프트웨어로 포스트 양자 암호 촉진
엔비디아, cuPQC 소프트웨어로 포스트 양자 암호 촉진 ST의 NFC 리더기, 비용 대비 뛰어난 성능의 내장형 비접촉식 인터랙션 구현
ST의 NFC 리더기, 비용 대비 뛰어난 성능의 내장형 비접촉식 인터랙션 구현 델 테크놀로지스, 2024년 AI 시대를 위한 광범위한 클라이언트 신제품 공개
델 테크놀로지스, 2024년 AI 시대를 위한 광범위한 클라이언트 신제품 공개 2023년 글로벌 반도체 장비 지출액 전년대비 1.3% 감소
2023년 글로벌 반도체 장비 지출액 전년대비 1.3% 감소 인텔, 세계 최초 AI 시대를 위해 설계한 ‘시스템즈 파운드리’ 출범
인텔, 세계 최초 AI 시대를 위해 설계한 ‘시스템즈 파운드리’ 출범 인텔, 엔터프라이즈용 AI PC를 위한 새로운 vPro 플랫폼 확대
인텔, 엔터프라이즈용 AI PC를 위한 새로운 vPro 플랫폼 확대 인텔, AI PC 소프트웨어 개발자 및 하드웨어 벤더를 위한 신규 프로그램 발표
인텔, AI PC 소프트웨어 개발자 및 하드웨어 벤더를 위한 신규 프로그램 발표 엔비디아, TSMC와 시높시스 생산 단계에 획기적인 컴퓨팅 리소그래피 플랫폼 지원
엔비디아, TSMC와 시높시스 생산 단계에 획기적인 컴퓨팅 리소그래피 플랫폼 지원 데이터브릭스, 범용 대형언어모델 ‘DBRX’로 효율적인 오픈소스 모델의 새로운 기준 제시
데이터브릭스, 범용 대형언어모델 ‘DBRX’로 효율적인 오픈소스 모델의 새로운 기준 제시