AI 반도체 기업인 그래프코어(Graphcore)는 지속적인 포플러(Poplar) 소프트웨어 개발키트(SDK) 최적화와 신규 IPU-POD 제품 출시를 통해 AI 훈련 성능 향상에 주력해 왔다. 특히, 지난 6월에 이어 두 번째로 진행된 MLPerf 테스트에서 기록적인 성능을 달성하고, 효율성과 성능, 소프트웨어 성숙도 등 그래프코어 IPU 시스템의 경쟁력을 다시한번 입증했다.
그래프코어는 호스트 서버와 AI 컴퓨팅을 분리하는 등 시스템 설계 단계부터 업계 내 다른 기업들과는 근본적으로 다른 혁신적 접근방식을 통해 최소 3개월마다 성능 향상을 위한 소프트웨어 업데이트를 진행하고 있으며, IPU를 위한 새로운 모델 및 워크로드를 구현하고 최적화하는 작업을 수행하고 있다.
그래프코어의 페브리스 모이잔(Fabrice Moizan) 글로벌 세일즈 부사장은 “AI는 기존의 컴퓨팅 방식과는 완전히 다른 새로운 차원의 프로세싱이 필요하며, 기존의 칩 구조의 한계를 벗어날 필요가 있다. 그래프코어는 최적화된 시스템 아키텍처와 소프트웨어를 통해 AI 애플리케이션을 매우 효율적으로 지원하고 있다.”고 밝혔다.
그래프코어 IPU 시스템, 엔비디아 DGX A100 성능 능가
그래프코어 IPU 시스템은 지속적인 소프트웨어 최적화를 통해 향상된 성능을 제공하고 있다. 특히, 이번 MLPerf 벤치마크에서 그래프코어 IPU-POD16은 컴퓨터 비전 모델 ResNet-50 훈련에 있어 엔비디아의 DGX A100을 능가하는 성능을 보였다. ResNet-50을 훈련하는데 엔비디아 DGX A100은 29.1분이 걸린데 반해, 그래프코어의 IPU-POD16은 28.3분을 기록했다. 이는 소프트웨어만으로 첫 MLPerf 테스트 결과 대비 24%의 성능 향상을 이룬 것으로, 통상적으로 ResNet-50 모델 학습에 GPU가 사용되고 있다는 점을 감안하면 이번 결과는 더욱 주목할 만하다.

그래프코어 IPU-POD16이 ResNet-50 훈련에서 엔비디아의 DGX A100을 능가하는 성능을 기록했다.
새로운 IPU-POD256, ResNet-50 모델 훈련 시간 단 3분대 기록
그래프코어는 또한 최근 새롭게 출시된 IPU-POD128 및 IPU-POD256에 대한 벤치마크 결과도 공개했다. 그래프코어는 MLPerf '상용화 가능(Commercially Available)' 부문에 해당 시스템에 대한 테스트 결과를 제출하며 지속적인 시스템 규모 확대 및 성능 향상을 위한 노력을 증명했다. 그래프코어 IPU 시스템 상 역대 최고의 성능을 자랑하는 IPU-POD128과 IPU-POD256의 경우 ResNet-50 모델 훈련에 걸린 시간은 각 5.67분, 3.79분에 불과했다.

그래프코어의 새로운 플래그십 제품 IPU-POD128과 IPU-POD256의 ResNet-50 모델 훈련 시간은 각 5.67분, 3.79분에 불과했다.
자연어 처리(NLP) 모델 BERT의 경우, 그래프코어는 IPU-POD16, IPU-POD64 및 IPU-POD128 훈련 데이터를 오픈(Open) 및 클로즈드(Closed) 부문 모두에 제출했다. 특히 오픈 부문에서 최신 IPU-POD128의 훈련 시간은 5.78분으로 월등한 성능을 보였다. 전반적으로 BERT 모델 훈련 성능은 지난 MLPerf 벤치마크 대비 IPU-POD16은 5%, IPU-POD64는 12%가 각각 향상됐다.
효율성을 고려한 획기적인 설계
MLPerf 테스트의 원 데이터를 살펴보면 각 벤더의 시스템과 연결된 호스트 프로세서의 수가 굉장히 많다는 점이 눈에 띈다. 일부 참가 기업의 경우, 두 개의 AI 프로세서 마다 하나의 CPU를 지정하기도 한다. 이에 반해, 그래프코어는 가장 낮은 호스트 프로세서 대 IPU 비율을 지속적으로 유지하고 있다. IPU는 데이터 이동에만 호스트 서버를 사용하며 런타임 시점에 호스트 서버가 코드를 발송할 필요가 없다. 따라서 IPU 시스템에 필요한 호스트 서버 수가 적은만큼, 더욱 유연하고 효율적인 확장이 가능해진다.
BERT-Large와 같은 자연어 처리 모델의 경우, IPU-POD64는 하나의 듀얼 CPU 호스트 서버만 필요로 한다. ResNet-50은 이미지 사전 처리를 위해 더 많은 호스트 프로세서 지원이 필요하므로 IPU-POD64당 4개의 듀얼 코어 서버가 지정된다. 이때 시스템 대비 호스트 프로세서 비율은 1:8 로, MLPerf에 참가한 다른 모든 시스템보다 낮은 비율을 자랑한다. 이번 MLPerf 1.1 벤치마크 테스트에서 그래프코어는 BERT 훈련에서 단 10.6분으로 가장 빠른 단일 서버 훈련 시간을 기록했다는 점도 눈 여겨 볼만 하다.

그래프코어는 BERT 훈련에서 단 10.6분으로 가장 빠른 단일 서버 훈련 시간을 기록했다.
진선옥 기자 (jadejin@all4chip.com)
저작권©올포칩 미디어. 무단전재 및 재배포를 금지합니다.
 IBM과 삼성, 전통적인 반도체 설계 한계를 뛰어넘는 새로운 반도체 기술 발표이번 발표는 전 세계적인 반도체 부족 사태로 인해 칩 연구 및 개발에 대한 투자의 중요성은 물론, 컴퓨터, 가전제품, 통신 장비, 운송 시스템 및 중요한 인프라에 활용되는 반도체 자체의 중요성이 증가한 가운데 이루어져 더욱 눈길을 끈다. 이번에 발표된 혁신적인 반도체 기술은 IBM과 삼성전자가 뉴욕 올버니 나노테크 연구단지에서 진행한 공동 연구의 결과로, 이 곳에서 연구원들은 논리 회로의 확장과 반도체 성능의 경계를 넓히기 위해 공공 및 민간 부문 파트너와 긴밀히 협력하고 있다.
IBM과 삼성, 전통적인 반도체 설계 한계를 뛰어넘는 새로운 반도체 기술 발표이번 발표는 전 세계적인 반도체 부족 사태로 인해 칩 연구 및 개발에 대한 투자의 중요성은 물론, 컴퓨터, 가전제품, 통신 장비, 운송 시스템 및 중요한 인프라에 활용되는 반도체 자체의 중요성이 증가한 가운데 이루어져 더욱 눈길을 끈다. 이번에 발표된 혁신적인 반도체 기술은 IBM과 삼성전자가 뉴욕 올버니 나노테크 연구단지에서 진행한 공동 연구의 결과로, 이 곳에서 연구원들은 논리 회로의 확장과 반도체 성능의 경계를 넓히기 위해 공공 및 민간 부문 파트너와 긴밀히 협력하고 있다. ST, 미래의 전기자동차 및 산업용 애플리케이션 촉진하는 새로운 실리콘 카바이드 디바이스 출시ST의 새로운 SiC 디바이스는 전기자동차의 트랙션 인버터, 온보드 충전기, DC/DC 컨버터는 물론, 전기식 친환경(e-Climate) 컴프레서 등의 고급 자동차 애플리케이션에 특히 최적화돼 있다. 이 최신 세대 제품은 산업용 애플리케이션인 모터 드라이브, 재생 에너지 컨버터, 에너지 스토리지 시스템, 통신 및 데이터센터 전원공급장치의 효율을 높이는 데 적합하다.
ST, 미래의 전기자동차 및 산업용 애플리케이션 촉진하는 새로운 실리콘 카바이드 디바이스 출시ST의 새로운 SiC 디바이스는 전기자동차의 트랙션 인버터, 온보드 충전기, DC/DC 컨버터는 물론, 전기식 친환경(e-Climate) 컴프레서 등의 고급 자동차 애플리케이션에 특히 최적화돼 있다. 이 최신 세대 제품은 산업용 애플리케이션인 모터 드라이브, 재생 에너지 컨버터, 에너지 스토리지 시스템, 통신 및 데이터센터 전원공급장치의 효율을 높이는 데 적합하다.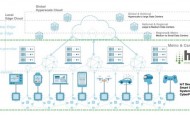 HIRO, 확장 가능한 차세대 에지 마이크로 데이터 센터 구축에지 컴퓨팅은 데이터에 대해 더 빠른 (중간 계층의) 릴레이 역할을 하며, 장치에서 시스템 전반에 영향을 주는 실시간 응답을 가능하게 한다. 에지 컴퓨팅은 클라우드의 AI에 의존하는 대신 AI를 기본적으로 지원하여 서비스와 애플리케이션의 수준을 크게 향상시킬 수 있다. 에지는 컴퓨팅을 에지에서 클라우드로 이동할 때 지능적인 의사 결정을 돕는 곳이다.
HIRO, 확장 가능한 차세대 에지 마이크로 데이터 센터 구축에지 컴퓨팅은 데이터에 대해 더 빠른 (중간 계층의) 릴레이 역할을 하며, 장치에서 시스템 전반에 영향을 주는 실시간 응답을 가능하게 한다. 에지 컴퓨팅은 클라우드의 AI에 의존하는 대신 AI를 기본적으로 지원하여 서비스와 애플리케이션의 수준을 크게 향상시킬 수 있다. 에지는 컴퓨팅을 에지에서 클라우드로 이동할 때 지능적인 의사 결정을 돕는 곳이다. 마이크로소프트, 애저 스페이스 확장해 우주 클라우드 시대 앞당긴다마이크로소프트는 지난해 10월 스페이스X, SES 등 인공위성 산업 리더들과 우주 클라우드 파트너십을 결성, 전 세계 다양한 산업을 위한 솔루션을 제공하는 애저 스페이스를 공개한 바 있다. 여기에, 이날 마이크로소프트는 인공위성과 애저 간 연결성 및 지리공간 기능을 확장하는 신규 파트너십과 혁신 기술을 발표했다.
마이크로소프트, 애저 스페이스 확장해 우주 클라우드 시대 앞당긴다마이크로소프트는 지난해 10월 스페이스X, SES 등 인공위성 산업 리더들과 우주 클라우드 파트너십을 결성, 전 세계 다양한 산업을 위한 솔루션을 제공하는 애저 스페이스를 공개한 바 있다. 여기에, 이날 마이크로소프트는 인공위성과 애저 간 연결성 및 지리공간 기능을 확장하는 신규 파트너십과 혁신 기술을 발표했다. 몰렉스, 키사 무선 커넥터 핵심기술 및 지적재산 인수몰렉스는 350개 이상의 특허출원을 포함하는 키사의 무선 칩-투-칩(chip-to-chip) 기술을 인수하면서, 근거리용 기기간 연결이 필요한 애플리케이션에 사용되는 높은 유연성의 케이블프리(cable-free) 커넥터 분야로 자사의 마이크로 커넥터 포트폴리오 확대를 가속화할 방침이다.
몰렉스, 키사 무선 커넥터 핵심기술 및 지적재산 인수몰렉스는 350개 이상의 특허출원을 포함하는 키사의 무선 칩-투-칩(chip-to-chip) 기술을 인수하면서, 근거리용 기기간 연결이 필요한 애플리케이션에 사용되는 높은 유연성의 케이블프리(cable-free) 커넥터 분야로 자사의 마이크로 커넥터 포트폴리오 확대를 가속화할 방침이다. 존슨콘트롤즈, 세계 최초로 스마트빌딩 제품에 ISA시큐어 CSA 인증 획득사이버보안 관련 위협이 증가하고 보안 수준이 낮은 빌딩 인프라에 잠재된 취약성에 대한 우려가 높아지는 이때 존슨콘트롤즈가 해당 인증을 취득했음은 의미가 있다. 존슨콘트롤즈의 요크 냉동기가 제어시스템 보안 국제표준규격인 ISA/IEC62443-4-2 정의에 따라 IACS 부품에 대한 보안 조건을 충족하고, 여기에 부합한 개발이 인증됨으로써 고객에게 신뢰를 주기 때문이다.
존슨콘트롤즈, 세계 최초로 스마트빌딩 제품에 ISA시큐어 CSA 인증 획득사이버보안 관련 위협이 증가하고 보안 수준이 낮은 빌딩 인프라에 잠재된 취약성에 대한 우려가 높아지는 이때 존슨콘트롤즈가 해당 인증을 취득했음은 의미가 있다. 존슨콘트롤즈의 요크 냉동기가 제어시스템 보안 국제표준규격인 ISA/IEC62443-4-2 정의에 따라 IACS 부품에 대한 보안 조건을 충족하고, 여기에 부합한 개발이 인증됨으로써 고객에게 신뢰를 주기 때문이다. 특화된 프로세싱, Arm 기반 클라우드 컴퓨팅의 시대를 열고 AWS 그래비톤의 혁신을 구현하다AWS 그래비톤 및 그래비톤2는 클라우드에서 Arm 기반 컴퓨팅의 이점과 다양한 산업에 걸쳐 고객과 개발자들에게 지속적으로 제공하는 유연성을 공개함으로써 이러한 Arm 기반 프로세서의 성장과 성공은 계속 진행 중임을 증명했습니다. Arm 기반 클라우드 인스턴스가 제공하는 가격 대비 성능 이점은 AWS 서비스 포트폴리오 전반으로 확대되고 있습니다:
특화된 프로세싱, Arm 기반 클라우드 컴퓨팅의 시대를 열고 AWS 그래비톤의 혁신을 구현하다AWS 그래비톤 및 그래비톤2는 클라우드에서 Arm 기반 컴퓨팅의 이점과 다양한 산업에 걸쳐 고객과 개발자들에게 지속적으로 제공하는 유연성을 공개함으로써 이러한 Arm 기반 프로세서의 성장과 성공은 계속 진행 중임을 증명했습니다. Arm 기반 클라우드 인스턴스가 제공하는 가격 대비 성능 이점은 AWS 서비스 포트폴리오 전반으로 확대되고 있습니다: ST, 생체인식 시스템 온 카드 및 dCVV 솔루션 지원하는 차세대 보안 마이크로컨트롤러 출시ST의 40nm eSTM 기술에 기반한 ST31N600은 생체인식 및 동적 카드 검증(dCVV: Dynamic Card Verification) 애플리케이션에 사용되는 추가 커넥티비티와 에너지 하베스팅용 회로를 통합한다. 이를 통해 배터리가 필요없는 스마트 카드를 구현해 비접촉식 및 온라인 거래에서 향상된 사용자 인증을 제공한다.
ST, 생체인식 시스템 온 카드 및 dCVV 솔루션 지원하는 차세대 보안 마이크로컨트롤러 출시ST의 40nm eSTM 기술에 기반한 ST31N600은 생체인식 및 동적 카드 검증(dCVV: Dynamic Card Verification) 애플리케이션에 사용되는 추가 커넥티비티와 에너지 하베스팅용 회로를 통합한다. 이를 통해 배터리가 필요없는 스마트 카드를 구현해 비접촉식 및 온라인 거래에서 향상된 사용자 인증을 제공한다. 유블럭스, GNSS 보정 데이터 수신기 신제품 2종 및 업그레이드된 ZED-F9P 고정밀 GNSS 수신기 출시업그레이드된 ZED-F9P 고정밀 GNSS 수신기 모듈 및 이와 함께 사용할 수 있는 GNSS 보정 데이터 수신기인 NEO-D9S 와 NEO-D9C를 활용함으로써, 고객은 잔디깎이 로봇, 무인 항공기(UAV), 반자율 또는 완전 자율 시스템 등 자신만의 특별한 애플리케이션용으로 확장가능한 솔루션을 조합하는 데 있어서 전례 없는 유연성을 누릴 수 있다.
유블럭스, GNSS 보정 데이터 수신기 신제품 2종 및 업그레이드된 ZED-F9P 고정밀 GNSS 수신기 출시업그레이드된 ZED-F9P 고정밀 GNSS 수신기 모듈 및 이와 함께 사용할 수 있는 GNSS 보정 데이터 수신기인 NEO-D9S 와 NEO-D9C를 활용함으로써, 고객은 잔디깎이 로봇, 무인 항공기(UAV), 반자율 또는 완전 자율 시스템 등 자신만의 특별한 애플리케이션용으로 확장가능한 솔루션을 조합하는 데 있어서 전례 없는 유연성을 누릴 수 있다. 마이크로일렉트로니카, 임베디드 업계 최초의 HaaS인 Planet Debug 출시Planet Debug 서비스형 하드웨어는 와이파이를 통해 프로그래밍 및 디버깅을 수행할 수 있는 세계 최초의 장치인 마이크로 일렉트로니카의 혁신적인 CODEGRIP에 의해 활성화된다. Planet Debug를 사용하면 시간과 비용을 절약할 수 있을 뿐 아니라 구매 전 시도를 통해 다른 하드웨어를 사고 새로운 소프트웨어를 배워 새로운 코드를 만들지 않고도 주변 장치, 디스플레이 및 MCU를 변경할 수 있게 된다.
마이크로일렉트로니카, 임베디드 업계 최초의 HaaS인 Planet Debug 출시Planet Debug 서비스형 하드웨어는 와이파이를 통해 프로그래밍 및 디버깅을 수행할 수 있는 세계 최초의 장치인 마이크로 일렉트로니카의 혁신적인 CODEGRIP에 의해 활성화된다. Planet Debug를 사용하면 시간과 비용을 절약할 수 있을 뿐 아니라 구매 전 시도를 통해 다른 하드웨어를 사고 새로운 소프트웨어를 배워 새로운 코드를 만들지 않고도 주변 장치, 디스플레이 및 MCU를 변경할 수 있게 된다. ST, 나노엣지 AI 스튜디오 업그레이드로 커넥티드 기기 및 산업용 장비를 위한 머신러닝 소프트웨어 개발 간소화새로운 버전의 나노엣지 AI 스튜디오는 AI 기능이 클라우드에서 엣지로 이동함에 따라 산업 공정을 근본적으로 개선하고, 유지관리 비용을 최적화하며, 로컬에서 데이터를 감지, 처리, 작동시키는 혁신 기능을 장비에서 구현해 지연시간 및 정보 보안을 개선하는 등의 엄청난 잠재력을 제조업체들에게 제공한다.
ST, 나노엣지 AI 스튜디오 업그레이드로 커넥티드 기기 및 산업용 장비를 위한 머신러닝 소프트웨어 개발 간소화새로운 버전의 나노엣지 AI 스튜디오는 AI 기능이 클라우드에서 엣지로 이동함에 따라 산업 공정을 근본적으로 개선하고, 유지관리 비용을 최적화하며, 로컬에서 데이터를 감지, 처리, 작동시키는 혁신 기능을 장비에서 구현해 지연시간 및 정보 보안을 개선하는 등의 엄청난 잠재력을 제조업체들에게 제공한다. 버티브, 엣지 인프라 구축을 위한 표준 모델 발표 (연구결과 발표)“엣지 구조요소 2.0: 즉시 구축 가능한 엣지 인프라 모델”이라는 제목의 이 보고서는 버티브가 2018년에 수행한 ‘엣지 구조요소 연구 및 분류(edge archetypes research and taxonomy)’를 토대로 하고 있다. 이번 연구에서는 위치와 외부 환경, 랙의 수, 전력 요건 및 가용성, 사이트 소유 여부, 패시브 인프라, 엣지 인프라 서비스 사업자, 구축할 사이트 수 같은 요인들을 추가로 반영해서 엣지 사이트를 분류했다.
버티브, 엣지 인프라 구축을 위한 표준 모델 발표 (연구결과 발표)“엣지 구조요소 2.0: 즉시 구축 가능한 엣지 인프라 모델”이라는 제목의 이 보고서는 버티브가 2018년에 수행한 ‘엣지 구조요소 연구 및 분류(edge archetypes research and taxonomy)’를 토대로 하고 있다. 이번 연구에서는 위치와 외부 환경, 랙의 수, 전력 요건 및 가용성, 사이트 소유 여부, 패시브 인프라, 엣지 인프라 서비스 사업자, 구축할 사이트 수 같은 요인들을 추가로 반영해서 엣지 사이트를 분류했다. 노르딕 세미컨덕터의 블루투스 솔루션을 채택한 이오플로우의 웨어러블 인슐린 펌프 시스템이오패치는 당뇨인이 하루 수차례의 인슐린 주사를 맞는 대신 3.5일마다 한번 몸에 부착하여 전용 컨트롤러 혹은 스마트폰 앱으로 인슐린 주입과 혈당 모니터링을 가능하게 한 체외형 인슐린 주입기로, 환자들의 삶의 질을 향상시킬 뿐만 아니라 병력노출을 최소화했다. 또한 클라우드 기반의 당뇨관리 프로그램인 ‘이오브릿지’와의 자동 연동을 통해 치료이력을 보호자 및 의료진과 공유할 수 있어 체계적인 질병관리가 가능한 통합관리 치료방법이다.
노르딕 세미컨덕터의 블루투스 솔루션을 채택한 이오플로우의 웨어러블 인슐린 펌프 시스템이오패치는 당뇨인이 하루 수차례의 인슐린 주사를 맞는 대신 3.5일마다 한번 몸에 부착하여 전용 컨트롤러 혹은 스마트폰 앱으로 인슐린 주입과 혈당 모니터링을 가능하게 한 체외형 인슐린 주입기로, 환자들의 삶의 질을 향상시킬 뿐만 아니라 병력노출을 최소화했다. 또한 클라우드 기반의 당뇨관리 프로그램인 ‘이오브릿지’와의 자동 연동을 통해 치료이력을 보호자 및 의료진과 공유할 수 있어 체계적인 질병관리가 가능한 통합관리 치료방법이다. 블루투스 LE를 활용한 무선 오디오 품질 향상블루투스 SIG(Special Interest Group)는 블루투스 무선 기술을 처음 도입할 당시부터 오디오를 이 기술의 주된 목표 시장으로 겨냥했다. 1999년에 블루투스 1.0이 발표되고서 얼마 지나지 않아 최초의 블루투스 컨수머 제품으로서 핸즈프리 모바일 헤드셋이 시장에 선을 보였다. 지금은 없어졌으나 중요한 컴퓨터 전시회였던 COMDEX에서 이 헤드셋이 ‘최고 제품상’을 수상하면서 블루투스의 상업적 성공을 예고했다.
블루투스 LE를 활용한 무선 오디오 품질 향상블루투스 SIG(Special Interest Group)는 블루투스 무선 기술을 처음 도입할 당시부터 오디오를 이 기술의 주된 목표 시장으로 겨냥했다. 1999년에 블루투스 1.0이 발표되고서 얼마 지나지 않아 최초의 블루투스 컨수머 제품으로서 핸즈프리 모바일 헤드셋이 시장에 선을 보였다. 지금은 없어졌으나 중요한 컴퓨터 전시회였던 COMDEX에서 이 헤드셋이 ‘최고 제품상’을 수상하면서 블루투스의 상업적 성공을 예고했다.
 인텔 파운드리, 고개구율 극자외선(High-NA EUV) 도입으로 칩 제조 분야 선도
인텔 파운드리, 고개구율 극자외선(High-NA EUV) 도입으로 칩 제조 분야 선도 NXP, 연간 기업 지속 가능성 보고서 - ESG 목표 달성 현황 공개
NXP, 연간 기업 지속 가능성 보고서 - ESG 목표 달성 현황 공개 로데슈바르즈, 획기적인 성능으로 무장한 R&S NGC100 파워 서플라이 제품군 신규 출시
로데슈바르즈, 획기적인 성능으로 무장한 R&S NGC100 파워 서플라이 제품군 신규 출시 IMDT와 Hailo가 합작하여 최고의 실시간 성능을 위한 엣지 AI 솔루션 출시
IMDT와 Hailo가 합작하여 최고의 실시간 성능을 위한 엣지 AI 솔루션 출시 콩가텍, 인텔 코어 i3 및 인텔 아톰 x7000RE 프로세서 탑재 SMARC 모듈 출시
콩가텍, 인텔 코어 i3 및 인텔 아톰 x7000RE 프로세서 탑재 SMARC 모듈 출시
- 인텔, 세계 최대규모 뉴로모픽 시스템 공개
- 마이크로칩, 항공기 전기화 전화를 간소화하는 통합 구동 파워 솔루션 출시
- 텔레다인르크로이, 광범위한 통신 기술 데이터를 원활하게 포착하는 프론트라인 X500e 출시
- TTTech Auto, 복잡한 소프트웨어 통합을 혁신할 차세대 스케줄러 ‘MotionWise Schedule’ 출시
- 아이스아이, 글로벌 SAR 리더십 확장을 위한 기업의 성장 펀딩 라운드 초과 달성
- 오나인솔루션즈, 생성형 AI 기술 적용해 ‘o9 Digital Brain’ 플랫폼 강화
그래픽 / 영상
 결정론, 새로운 이더넷 애플리케이션을 열다
결정론, 새로운 이더넷 애플리케이션을 열다 AMD, 새로운 2세대 버설 적응형 SoC로 AI 기반 임베디드 시스템의 종단간 가속 지원
AMD, 새로운 2세대 버설 적응형 SoC로 AI 기반 임베디드 시스템의 종단간 가속 지원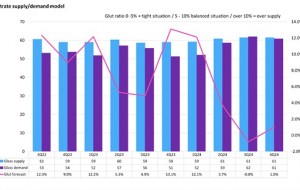 2024년, 디스플레이 글래스 산업 공급부족 우려
2024년, 디스플레이 글래스 산업 공급부족 우려
많이 본 뉴스
 마우저, 엣지 임펄스와 글로벌 협력으로 머신러닝 개발에 대한 접근성 확대
마우저, 엣지 임펄스와 글로벌 협력으로 머신러닝 개발에 대한 접근성 확대 델 테크놀로지스, 2024년 AI 시대를 위한 광범위한 클라이언트 신제품 공개
델 테크놀로지스, 2024년 AI 시대를 위한 광범위한 클라이언트 신제품 공개 두산디지털이노베이션, 아시아 최대 보안 전시회서 사이버보안 솔루션 선보여
두산디지털이노베이션, 아시아 최대 보안 전시회서 사이버보안 솔루션 선보여 로데슈바르즈, NTN NB-IoT 테스트 케이스의 신규 GCF 인증 획득
로데슈바르즈, NTN NB-IoT 테스트 케이스의 신규 GCF 인증 획득 테스트웍스, 6년 연속 데이터바우처 지원사업 공급기업 선정
테스트웍스, 6년 연속 데이터바우처 지원사업 공급기업 선정 헥사곤-스맥, 스마트 제조 기술 개발 위한 MOU 체결
헥사곤-스맥, 스마트 제조 기술 개발 위한 MOU 체결 로지텍, 플래그십 무선 게이밍 헤드셋 ‘A50 X’ 출시
로지텍, 플래그십 무선 게이밍 헤드셋 ‘A50 X’ 출시 마이크로칩, 더 큰 메모리 용량과 속도를 제공하는 직렬 SRAM 확장 제품군 출시
마이크로칩, 더 큰 메모리 용량과 속도를 제공하는 직렬 SRAM 확장 제품군 출시 ST, 지능형 기능과 효율성 결합한 하이사이드 스위치 출시
ST, 지능형 기능과 효율성 결합한 하이사이드 스위치 출시 ST, 비용 효율적인 차세대 마이크로컨트롤러 위해 20nm 장벽 극복
ST, 비용 효율적인 차세대 마이크로컨트롤러 위해 20nm 장벽 극복