
DSP, GPU 및 FPGA는 CPU 가속기로 동작하면서 성능은 물론 전력 효율을 향상시키는 이점을 제공한다. 다양한 종류의 컴퓨팅 아키텍처를 이용할 수 있으므로 설계자는 일관된 방법을 통해 성능과 전력 효율을 비교할 필요가 있다. 수용되는 방법은 초당 부동 소수점 연산(FLOPs)을 측정하는 것이다. 여기서 FLOPs는 IEEE 754 표준에 따른 단정밀도(32비트) 또는 배정밀도(64비트) 수의 덧셈 또는 곱셈으로 정의된다. 나눗셈, 제곱근, 삼각 함수 연산과 같은 고차 함수는 가산기와 곱셈기를 사용하여 구성할 수 있다. 이러한 연산 외에도 고속 푸리에 변환(FFT)과 행렬 연산과 같은 다른 일반적인 함수는 가산기와 곱셈기를 둘 다 필요로 하기 때문에 통상적으로 이러한 모든 아키텍처에서 1:1 비의 가산기와 곱셈기가 사용된다.
DSP, GPU, FPGA 성능 비교
우리는 최고 FLOPS 정격 수치를 기초로 DSP, GPU, FPGA 아키텍처의 성능을 비교한다. 최고 FLOPS 정격 수치는 가산기와 곱셈기의 합을 최대 동작 주파수로 곱하여 결정된다. 이것은 실제적으로는 결코 달성할 수 없는 계산 상의 이론적인 한계를 나타낸다. 일반적으로 모든 계산 유닛을 항상 가동할 수 있게 하는 유용한 알고리즘을 구현하는 것은 가능하지 않기 때문이다. 그러나 이 수치는 유용한 비교 척도를 제공한다.
DSP 피크 GFLOPs
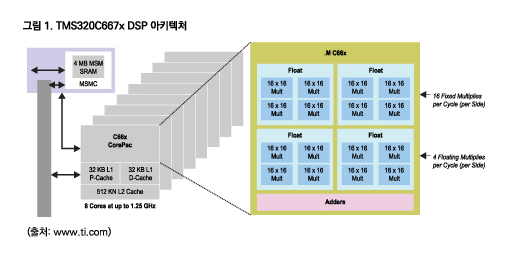
먼저 TI(Texas Instruments)의 TMS320C667x DSP를 살펴본다. 이 DSP는 8개 DSP 코어를 포함하며, 각각의 코어는 2개의 프로세싱 서브시스템을 포함한다. 각 서브시스템은 4개의 단정밀도 부동 소수점 가산기와 4개의 단정밀도 부동 소수점 곱셈기를 포함한다. 전체로 64개 가산기와 64개 곱셈기가 있다. 현재 제공되는 가장 빠른 버전은 1.25GHz에서 실행하고, 최고 60기가플롭스(GFLOPs)를 제공한다.
GPU 피크 GFLOPs
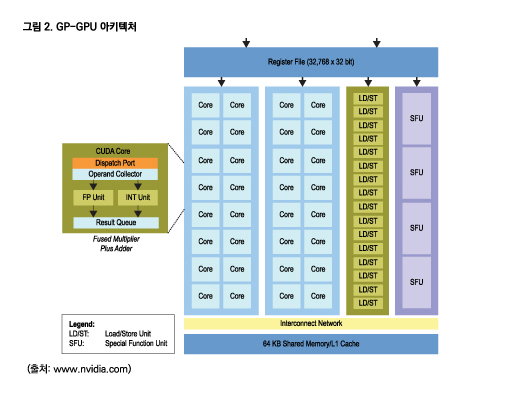
가장 강력한 GPU 중 하나는 NVIDIA의 테슬라 K20이다. 이 GPU는 CUDA 코어를 기반으로 하며, 각각의 코어는 단정밀도 부동 소수점 구성으로 클록 사이클당 하나의 명령어를 실행할 수 있는 단일 부동 소수점 다중-가산기 유닛을 탑재한다. 각 스트리밍 멀티프로세서(SMX) 프로세싱 엔진에는 192개 CUDA 코어가 있다. K20는 공정 수율 등의 문제로 단 13개만 사용할 수 있지만 실제로 15개 SMX를 포함하고 있다. 전체로는 2,496개의 사용 가능한 CUDA 코어를 제공하며, 클록 사이클당 2 FLOPs를 처리하고 최대 706MHz에서 실행한다. K20은 3,520 GFLOPs의 최고 단정밀도 부동 소수점 성능을 제공한다.
FPGA 피크 GFLOPs
알테라는 현재 FPGA에 하드구현 부동 소수점 엔진을 제공하고 있다. 단정밀도 부동 소수점 곱셈기와 가산기가 프로그래머블 로직 구조 전체에 임베디드된 하드 DSP 블록에 통합되었다. 알테라의 중급 Arria® 10 FPGA 제품군으로 중간 크기의 FPGA는 10AX066이다. 이 디바이스는 각 블록에서 클록 사이클당 2 FLOPs를 실행할 수 있는 1,678개 DSP 블록을 탑재해, 전체로는 각 클록 사이클당 3,376 FLOPs를 제공한다. 450MHz의 정격 속도에서(이것은 부동 소수점의 수치이며, 고정 소수점 모드에서는 더 높다), 이 디바이스는 1,520 GFLOPs를 제공한다. 유사한 방식으로 계산하면 알테라는 하이 엔드 Stratix® 10 FPGA에서 10,000 GFLOPs 또는 10 TeraFLOPs의 단정밀도 성능을 제공한다고 말할 수 있다. 이것은 클록 속도의 증가와 훨씬 많은 DSP 컴퓨팅 리소스를 갖는 대형 디바이스의 결합으로 달성된 것이다.
프로그래머블 로직을 사용하는 FPGA의 부동 소수점
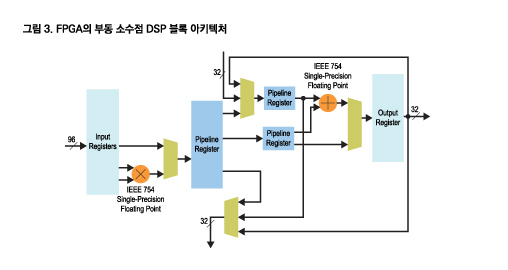
부동 소수점은 FPGA의 프로그래머블 로직을 사용하는 FPGA에서 언제나 사용 가능했다. 더욱이 부동 소수점을 기반으로 하는 프로그래머블 로직의 경우 임의적인 정밀도 수준을 구현할 수 있으며, 산업 표준 단정밀도 및 배정밀도에 제한되지 않는다. 알테라는 7가지의 다양한 부동 소수점 정밀도 수준을 제공한다. 그러나 프로그래머블 로직 구현을 사용하는 특정 FPGA에 대한 최고 부동 소수점 성능을 결정하는 문제는 전혀 간단하지 않다. 따라서 알테라 FPGA의 최고 부동 소수점 정격 수치는 전적으로 하드구현 부동 소수점 엔진 성능을 기반으로 하며, 프로그래머블 로직은 부동 소수점에 사용되지 않는다고 가정한다. 프로그래머블 로직은 오히려 설계의 다른 부분인 데이터 제어와 스케줄링 회로, I/O 인터페이스, 내부 및 외부 메모리 인터페이스 및 기타 필요한 기능 등에 사용된다고 가정한다.
부동 소수점 성능을 결정하는 문제의 어려움
프로그래머블 로직을 사용하는 부동 소수점 성능의 계산을 매우 어렵게 만드는 몇 가지 요인들이 존재한다. 한 개의 단정밀도 부동 소수점 곱셈기와 가산기를 구성하는 로직의 크기는 FPGA 벤더의 부동 소수점 IP(intellectual property) 사용자 가이드를 참조하여 결정할 수 있다. 그러나 한 가지 핵심적인 정보는 사용자 가이드에 나와 있지 않은데, 그것은 필요한 라우팅 리소스이다. 부동 소수점을 구현하려면 엄청난 양의 프로그래머블 라우팅(프로그래머블 LE 간 인터커넥트)을 소비하는 대형 배럴 시프터가 필요하다.
모든 FPGA는 로직을 지원하는 일정한 양의 인터커넥트를 갖추고 있다. 이 크기는 일반적인 부동 소수점 FPGA 설계가 사용하는 양을 기초로 정한다. 그러나 유감스럽게도 부동 소수점은 대부분의 고정 소수점 설계보다 훨씬 높은 수준의 인터커넥트를 필요로 한다. 부동 소수점의 단일 인스턴스를 생성할 경우 이것은 사용되는 LE(logic element)의 일반 영역에서 라우팅 리소스를 가져올 수 있다. 그러나 다수의 부동 소수점 연산을 함께 결합하는 경우 라우팅 혼잡을 초래하며, 이는 비교 가능한 고정 소수점 FPGA 설계보다 훨씬 높은 로직 사용뿐 아니라 설계의 달성 가능한 클록 속도를 크게 낮추는 요인이 된다.
알테라는 이러한 문제를 “융합 데이터 경로(fused datapath)”라고 부르는 고유의 합성 기법으로 일정 수준으로 완화하고 로직 패브릭에서 매우 큰 부동 소수점 설계를 구현할 수 있게 하면서 단일 정밀도의 경우 27x27개 곱셈기와 배정밀도의 경우 54x54개를 이용한다.
또한 FPGA 로직은 100% 이용할 수 없다. 사용 가능한 로직 리소스의 많은 부분을 설계가 차지하고 있기 때문에 타이밍 클로저를 달성할 수 있는 클록 속도 또는 fMAX가 감소되며 결과적으로 타이밍 클로저를 전혀 달성할 수 없다. 통상적으로 로직의 70 - 90%를 실제로 사용할 수 있는데, 높은 밀도의 부동 소수점 설계에서는 이 범위가 더 낮아지는 경향이 있다.
부동 소수점 설계 벤치마킹
이러한 이유로 프로그래머블 로직으로 구현하는 경우 FPGA의 부동 소수점 성능을 계산하는 것은 거의 불가능하다. 대신, 최선의 방법은 타이밍 클로저 과정을 포함하는 벤치마크 부동 소수점 설계를 구성하는 것이다. 대안적인 방법으로 FPGA 벤더는 특정 FPGA에서 무엇이 가능한지를 평가하는 데 많은 도움을 줄 수 있는 이와 같은 설계를 제공할 수 있다.
알테라는 기본 설계뿐 아니라 복잡한 부동 소수점 설계를 포함하는 28nm FPGA 상에 벤치마크 설계를 제공한다. 발표된 결과에 의하면 28nm FPGA에서 FFT와 같은 단순한 알고리즘의 경우 수백 GFLOPs를 달성하고 QR과 콜레스키 분해(Cholesky decomposition)와 같은 복잡한 알고리즘의 경우에는 100을 약간 넘는 GFLOP를 달성할 수 있는 것으로 나타났다.
* 벤치 마크 결과에 대해서는 레이더 처리: FPGA 또는 GPU(PDF) 기술자료를 참조한다.
이 밖에 써드파티 기술 분석 회사인 버클리 디자인 테크놀로지(BDTI, Berkeley Design Technology, Inc.)는 알테라의 28nm FPGA 상에서 복잡한 고성능 부동 소수점 DSP 설계에 대한 독립적인 분석을 수행했다.
* 이 독립적인 분석에 대한 자세한 내용은 BDTI에서 작성한 알테라 28nm FPGA 상에서 BDTI가 수행한 부동 소수점 DSP 설계 흐름 및 성능에 대한 독립적 분석(PDF) 기술자료를 참조한다.
또한 다른 많은 부동 소수점 벤치마크 설계가 알테라의 28nm Stratix V FPGA 상에서 OpenCL™을 사용해 구현되었으며 요청 시 구입할 수 있다. 이들 설계는 하드구현 부동 소수점 DSP 블록 아키텍처로 인해 획기적인 성능 향상을 제공하는 Arria 10 FPGA로 이행하는 과정에 있다.
FPGA GFLOPs를 계산시 피해야 하는 방법
다시 반복하지만 부동 소수점은 주로 프로그래머블 로직으로 구현하면서 고정 소수점 곱셈기 리소스를 사용하는 FPGA에서 언제나 가능했다. 그러나 실제 성능과 처리 성능에 존재하는 일정한 모호함으로 인해 일부에서는 매우 공격적인 마케팅 주장을 내놓고 있다. 우리는 사례 연구로 자일링스(Xilinx)의 28nm 및 20nm FPGA를 사용하여 어떻게 그와 같은 인위적인 벤치마크를 구성할 수 있는지에 대한 실제 예를 제시한다.
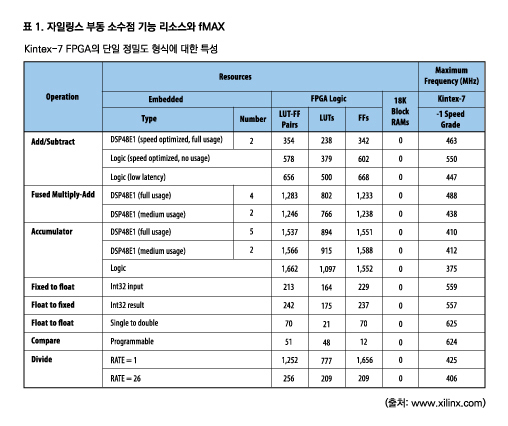
자일링스가 28nm 공정에 구축한 Kintex-7 FPGA에 대한 단일 부동 소수점 기능 구성과 성능 결정에 사용된 리소스 정보에 대해서는 표 1을 참조한다.
** Virtex-7 디바이스는 Kintex-7 디바이스와 동일한 코어 아키텍처를 공유한다. 따라서 표 1의 수치는 아래의 예에 대한 기준으로 사용할 수 있다.
자일링스에서 제공하는 최대 로직 밀도 28nm 디바이스는 Virtex-7 XC7V2000T 디바이스로 18x25개 고정 소수점 곱셈기와 함께 1,954.56K 로직 셀(LC)과 2,160 DSP 슬라이스를 갖는다.
벤치마킹에 융합된 곱셈-덧셈 기능을 선택한다면 DSP 슬라이스가 부족해 단 1,440개 유닛만 구성할 수 있다. 또한 정격 속도는 최고 속도 디바이스에서 단일 인스턴스에 대해 438MHz이기 때문에 곱셈기-가산기 기능이 부동 소수점 아키텍처에 사용되는 표준 아키텍처이긴 하지만 최고 GFLOPs 주장으로는 빈약한 선택이다.
부동 소수점 정격 수치를 극대화하려면 최상의 선택은 덧셈/뺄셈 기능을 사용하는 것이다. 최고의 전략은 DSP48E 슬라이스를 완전히 소모할 때까지 가능한 많은 가산기를 구성하고 순수한 로직으로 나머지 가산기를 구성하는 것이다. DSP 리소스 가산기는 2개의 DSP 슬라이스와 354개 LUT-FF 쌍(또는 LC)을 필요로 하며 단일 인스턴스는 463MHz에서 동작할 수 있다. 로직 기반 가산기는 578개 LC를 사용하며 단일 인스턴스는 550MHz에서 실행할 수 있다.
우리는 100% 로직과 100% DSP 슬라이스를 사용한다고 가정하며, 이는 모든 로직을 사용하기 위해 충분한 라우팅을 제공해야 한다는 것을 의미한다.
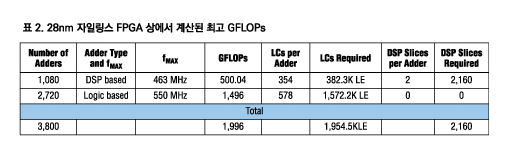
이 방법을 사용해 자일링스는 1,996 GFLOPs의 단정밀도 부동 소수점 성능을 주장할 수 있었다.
이와 유사하게 20nm에서 자일링스에서 제공하는 최대 로직 밀도 디바이스는 UltraScale XCVU440 디바이스이다. 이것은 4,407.48K LC 및 2,880 DSP 슬라이스를 갖는다(이들 각각은 18x27개 고정 소수점 곱셈기를 지원한다). 표 1은 디바이스 코어 아키텍처가 매우 유사하기 때문에 20nm Ultrascale 디바이스에도 적용할 수 있다. 20nm 공정은 최대 주파수를 12% 정도 증가시킨다고 한다.
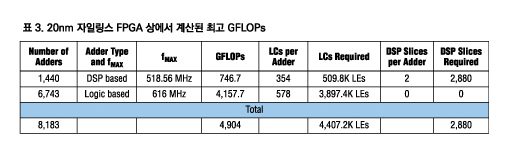
이 숫자는 자일링스가 주장하는 수치로, GFLOPs를 결정하는 데 사용되는 방법은 제공되지 않았다.
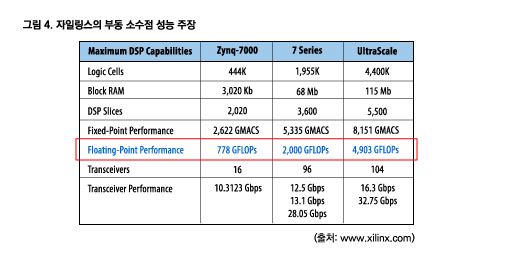
이 계산에 사용된 가정은 다음과 같다.
• 부동 소수점 가산기만 사용되었고 부동 소수점 곱셈기는 전혀 사용되지 않았다.
• FPGA 로직의 100%가 사용되었다.
• 완벽한 설계를 위한 타이밍이 단일 부동 소수점 연산의 fMAX에서 클로징되었다.
• 메모리 인터페이싱, 제어 회로 등에 사용 가능한 로직 리소스가 전혀 없었다.
• 선택된 디바이스는 FPGA 제품군의 DSP가 풍부한 제품이 아니라 프로토타입 플랫폼으로 ASIC 로직을 에뮬레이팅하는 데 유용한 디바이스에 가깝다.
대부분의 컴퓨터 아키텍처에서 부동 소수점 곱셈기와 가산기의 1:1 비율을 유지하는 이유가 있다. 곱셈기를 사용하는 애플리케이션은 행렬 곱셈, FFT를 비롯해 제곱근, 삼각 함수와 같은 고차 수학 함수, 로그, 행렬 변환 및 기타 선형 대수 집중 설계를 포함한다. 모든 유용한 부동 소수점 애플리케이션은 많은 수의 부동 소수점 곱셈기를 필요로 한다. 따라서 이는 컴퓨터 아키텍처에서 동일한 수의 곱셈기와 가산기를 제공하는 실제적인 이유이다. 곱셈기 없이 부동 소수점 가산기만 사용하면서 높은 정격 수치를 주장할 수 있지만 그러한 설계는 애플리케이션 이점이 전혀 없다.
경험이 풍부한 모든 FPGA 설계자는 알고 있듯이 사용하는 로직의 비율이 높아질수록 설계 fMAX가 감소한다. 일반적으로 80% 이상의 로직 사용은 타이밍 클로저를 달성할 수 있는 클록 속도에서 상당한 성능 저하를 초래한다. 더욱이 다른 기능들을 위해 상당한 양의 로직이 필요하며, 이는 부동 소수점 계산을 위해 사용 가능한 로직을 더욱 감소시킨다.
또한 FPGA 제품군의 선택은 중요하다. 선택된 제품군은 매우 고가의 디바이스로서 일반적으로 디바이스 비용과 전력 소모가 중요한 요소가 아닌 ASIC 프로토타이핑 애플리케이션에 사용된다. DSP 애플리케이션에 최적화된 FPGA 제품군을 사용할 경우 GFLOPs 계산을 대폭 줄일 수 있다.
여기에서 다루지는 않지만 FPGA 벤더의 초기 소비전력 예측기(power estimator)를 사용할 수 있다. 표 3에 정의된 모든 리소스와 fMAX를 사용하면 수백 와트의 전력 소비가 나온다. 이 특정 FPGA는 클록 속도와 토클 속도가 낮은 ASIC 프로토타이핑 애플리케이션을 위해 만들어졌다. 높은 클록 속도와 토클 속도는 디바이스의 VCC 전류와 소모 전력 성능을 넘어 전력 소비를 크게 증가시킨다.
간단히 말하면 이것은 업계에서 인정하는 벤치마킹 방법이 아니다. 따라서 이러한 방법을 사용하여 얻은 수치는 다른 반도체 회사의 최고 부동 소수점 성능 주장과 비교하는 데 사용되어서는 안 된다. 최고 GFLOPs 수치는 특정 디바이스의 달성 가능한 성능을 나타내야 한다. 물론 거의 모든 알고리즘이 모든 계산 유닛에서 100% 듀티 사이클로 유용한 계산을 수행할 수 있는 것은 아니기 때문에 일부 디레이팅은 필요할 수 있다.
결론
현재 하드구현 부동 소수점 DSP 블록을 탑재한 FPGA를 구입할 수 있으며, 이들 FPGA는 중급 Arria 10 디바이스에서 160 ~ 1,500 GFLOPs, 하이 엔드 Stratix 10 디바이스에서는 최대 10,000 GFLOPs의 단정밀도 성능을 제공한다. 이 최고 GFLOPs 지표는 CPU, GPU, DSP에 사용되는 투명한 동일한 방법을 바탕으로 계산되었다.
이 방법은 설계자에게 디바이스의 최고 부동 소수점 컴퓨팅 성능과 매우 다른 아키텍처와 기본적인 비교를 위한 신뢰할 수 있는 기법을 제공한다. 다음 수준의 비교는 관심있는 플랫폼 상에서 구현되는 대표적인 벤치마크 설계를 기반으로 해야 한다.
하드 부동 소수점 회로가 없는 FPGA의 경우 벤더가 계산하는 이론적인 GFLOPs 수치를 사용하는 것은 매우 신뢰성이 떨어진다. 500 GFLOPs 이상에서 로직 구현을 기반으로 하는 모든 FPGA 부동 소수점 주장은 상당히 의심스러운 관점에서 바라보아야 한다. 이 경우 상대적인 판단을 하기 위해서는 대표적인 벤치마크 설계 구현이 필수적이다. 또한 달성된 클록 속도와 함께 로직, 메모리 및 기타 리소스를 보여주는 FPGA 컴파일 리포트가 제공되어야 한다. 그리고 이보다 더욱 바람직한 것은 특정 성능 수준을 주장하는 모든 업체는 컴파일된 설계 파일을 제공함으로써 결과를 재현할 수 있도록 해야 한다.
추가 정보
• 배경 설명: 업계 최초 부동 소수점 FPGA
• 기술자료: 레이더 처리: FPGA GPU
• 기술자료: 알테라 28nm FPGA 상에서 BDTI가 수행한 부동 소수점 DSP 설계 흐름 및 성능에 대한 독립적 분석
저작권©올포칩 미디어. 무단전재 및 재배포를 금지합니다.
 GaN 기술의 혁신을 통한 커넥티드 카의 진화GaN 기술은 불가능하다고 생각했던 것을 가능하게 만든다는 점에서 파괴적이라 할 수 있다. eGaN 기술은 실리콘 기반 MOSFET에 비해 가격대비 뛰어난 성능을 제공하는 것은 물론, 10배 더 빠르고, 획기적으로 소형화가 가능하다.
GaN 기술의 혁신을 통한 커넥티드 카의 진화GaN 기술은 불가능하다고 생각했던 것을 가능하게 만든다는 점에서 파괴적이라 할 수 있다. eGaN 기술은 실리콘 기반 MOSFET에 비해 가격대비 뛰어난 성능을 제공하는 것은 물론, 10배 더 빠르고, 획기적으로 소형화가 가능하다.  다중 GSPS 컨버터 동기화의 테스트 방법다중 컨버터의 동기화는 일반적으로 레이더, 전자전(electronic warfare, EW), 초음파 및 기타 다중 채널 애플리케이션 등 디지털 빔 포밍 기술을 통해 폭넓은 데이터 분야를 다루는데 사용되는 애플리케이션에 유용하다.
다중 GSPS 컨버터 동기화의 테스트 방법다중 컨버터의 동기화는 일반적으로 레이더, 전자전(electronic warfare, EW), 초음파 및 기타 다중 채널 애플리케이션 등 디지털 빔 포밍 기술을 통해 폭넓은 데이터 분야를 다루는데 사용되는 애플리케이션에 유용하다.  ‘FPGA For DUMMIES’ FPGA 세계를 완전 해부한다!FPGA는 설계자가 현장에서 맞춤형 디지털 로직을 프로그래밍할 수 있는 집적 회로입니다. FPGA는 1980년대 이래로 주변에서 접할 수 있었으며 처음에는 모든 설계 팀이 맞춤형 로직을 작성할 수 있도록 구상되었습니다.
‘FPGA For DUMMIES’ FPGA 세계를 완전 해부한다!FPGA는 설계자가 현장에서 맞춤형 디지털 로직을 프로그래밍할 수 있는 집적 회로입니다. FPGA는 1980년대 이래로 주변에서 접할 수 있었으며 처음에는 모든 설계 팀이 맞춤형 로직을 작성할 수 있도록 구상되었습니다.  즉각적 만족이 필요한 첨단 기술세계오늘날의 개발자들은 시장 출시 시점을 앞당기기 위해 크리스탈 발진기 등의 애플리케이션 구성 부품에 대해 짧은 납기 기간을 요구하고 있으며 이 같은 요구가 수용되는 것에 대한 만족을 즉각적으로 표출하는 경우가 많다.
즉각적 만족이 필요한 첨단 기술세계오늘날의 개발자들은 시장 출시 시점을 앞당기기 위해 크리스탈 발진기 등의 애플리케이션 구성 부품에 대해 짧은 납기 기간을 요구하고 있으며 이 같은 요구가 수용되는 것에 대한 만족을 즉각적으로 표출하는 경우가 많다.  자동차 및 산업용 애플리케이션을 위한 65V 500mA 스텝다운 컨버터자동차와 산업용 시스템에서 기계식 기능을 전자 장치로 교체하는 경향이 갈수록 더 확산됨으로써 이들 시스템에서 마이크로컨트롤러, 신호 프로세서, 센서, 여타 전자 장치의 숫자가 전반적으로 빠르게 늘어나고 있다.
자동차 및 산업용 애플리케이션을 위한 65V 500mA 스텝다운 컨버터자동차와 산업용 시스템에서 기계식 기능을 전자 장치로 교체하는 경향이 갈수록 더 확산됨으로써 이들 시스템에서 마이크로컨트롤러, 신호 프로세서, 센서, 여타 전자 장치의 숫자가 전반적으로 빠르게 늘어나고 있다.  휴먼 인터페이스 설계를 위한 3가지 해법정전식 터치 감지 솔루션은 사물 인터넷(Internet of Things), 홈/빌딩 오토메이션, 소비자 및 산업용 시장을 위한 인간-기계 인터페이스(HMI)를 개발하는 시스템 디자이너에게 있어 매우 중요한 툴이다. 특히, C8051F97x 저전력 정전식 감지 마이크로컨트롤러(MCU) 제품군 같은 정전식 터치 솔루션은 HMI 설계자들이 자주 겪는 세 가지 문제를 해결해 준다.
휴먼 인터페이스 설계를 위한 3가지 해법정전식 터치 감지 솔루션은 사물 인터넷(Internet of Things), 홈/빌딩 오토메이션, 소비자 및 산업용 시장을 위한 인간-기계 인터페이스(HMI)를 개발하는 시스템 디자이너에게 있어 매우 중요한 툴이다. 특히, C8051F97x 저전력 정전식 감지 마이크로컨트롤러(MCU) 제품군 같은 정전식 터치 솔루션은 HMI 설계자들이 자주 겪는 세 가지 문제를 해결해 준다. 무선 충전 시스템의 전력 계측IPT(유도 전력 전송)라고도 불리는 무선 충전은 현재 개발되고 있는 기술로, 주요 적용 분야는 접촉 없이 배터리 구동 장치를 충전하는 용도이다. 이 방식으로 충전할 수 있는 장치로는 휴대 전화, 태블릿, 노트북 컴퓨터 등이 있다. 무선 충전 기술은 물리적인 연결을 할 필요가 없고 충전 중인 장치를 즉시 이동할 수 있으므로 매우 편리한 기술이다.
무선 충전 시스템의 전력 계측IPT(유도 전력 전송)라고도 불리는 무선 충전은 현재 개발되고 있는 기술로, 주요 적용 분야는 접촉 없이 배터리 구동 장치를 충전하는 용도이다. 이 방식으로 충전할 수 있는 장치로는 휴대 전화, 태블릿, 노트북 컴퓨터 등이 있다. 무선 충전 기술은 물리적인 연결을 할 필요가 없고 충전 중인 장치를 즉시 이동할 수 있으므로 매우 편리한 기술이다.  미래의 자동차 기술에 눈을 달아주는 TI자동차는 새로운 최첨단 기술을 포함하면서 점점 똑똑해지고, 이로 인해 운전자는 안전하고 보다 즐겁게 운전을 할 수 있게 되었다. 도로 사고를 줄인다는 목표로 이런 새로운 첨단 운전자 지원 시스템(ADAS) 애플리케이션은 대규모 정보 처리와 특수 병렬 장치를 사용하는 한편 환경 문제도 생각하여 동력 소비도 관리한다.
미래의 자동차 기술에 눈을 달아주는 TI자동차는 새로운 최첨단 기술을 포함하면서 점점 똑똑해지고, 이로 인해 운전자는 안전하고 보다 즐겁게 운전을 할 수 있게 되었다. 도로 사고를 줄인다는 목표로 이런 새로운 첨단 운전자 지원 시스템(ADAS) 애플리케이션은 대규모 정보 처리와 특수 병렬 장치를 사용하는 한편 환경 문제도 생각하여 동력 소비도 관리한다. 최신 고속 RF 트랜시버 설계를 지원하는 개발 에코시스템컨버터가 RF 프런트엔드에 다가갈수록 부품과 기능, 폭넓은 개발 에코시스템에 대한 엄격한 요건들이 새롭게 생겨난다.
최신 고속 RF 트랜시버 설계를 지원하는 개발 에코시스템컨버터가 RF 프런트엔드에 다가갈수록 부품과 기능, 폭넓은 개발 에코시스템에 대한 엄격한 요건들이 새롭게 생겨난다. 매우 낮은 인덕터 DCR 감지와 빠른 과도 응답, 위상당 30A를 제공하는 고효율 다상 전원LTC3875는 최신 고속, 고용량 데이터 프로세싱 시스템, 텔레콤 시스템, 산업 장비 및 DC 전력 분배 시스템의 전력 밀도 요건을 만족하는 다양한 기능의 듀얼 출력 동기식 벅 컨트롤러이다.
매우 낮은 인덕터 DCR 감지와 빠른 과도 응답, 위상당 30A를 제공하는 고효율 다상 전원LTC3875는 최신 고속, 고용량 데이터 프로세싱 시스템, 텔레콤 시스템, 산업 장비 및 DC 전력 분배 시스템의 전력 밀도 요건을 만족하는 다양한 기능의 듀얼 출력 동기식 벅 컨트롤러이다.  최상의 가치와 최적화를 실현한 자일링스의 올 프로그래머블 로우-엔드 포트폴리오비용에 민감한 애플리케이션을 위해 최신 올 프로그래머블(All Programmable) 디바이스는 새로운 차원의 정교하면서도 다양한 요건을 만족해야 한다. 컨수머 및 자동차, 산업 및 의료, 통신 분야의 저가 시스템들은 와트 당 최고 성능은 물론, 첨단 프로세싱을 위한 프로그래머블 로직 디바이스를 필요로 할 수도 있으며, 혹은 간단하게 기능 브리징 만을 필요로 할 수 있다.
최상의 가치와 최적화를 실현한 자일링스의 올 프로그래머블 로우-엔드 포트폴리오비용에 민감한 애플리케이션을 위해 최신 올 프로그래머블(All Programmable) 디바이스는 새로운 차원의 정교하면서도 다양한 요건을 만족해야 한다. 컨수머 및 자동차, 산업 및 의료, 통신 분야의 저가 시스템들은 와트 당 최고 성능은 물론, 첨단 프로세싱을 위한 프로그래머블 로직 디바이스를 필요로 할 수도 있으며, 혹은 간단하게 기능 브리징 만을 필요로 할 수 있다.  NFC 기술을 통한 소비자 마케팅의 변화NXP는 향후 몇 년 내에 NFC가 우리 일상 생활에 상당한 변화를 가지고 올 것으로 기대하고 있다. 이는 시장 수치들만 봐도 충분히 짐작할 수 있다. 통신거리 100m 이상의 NFC 기반 단말기 제품들이 2012년에 상용화되었는데, ABI 리서치의 조사에 따르면 2014년경에는 NFC 단말기의 보급률이 5억대를 초과하여 2017년경에는 20억 대에 이를 것으로 전망되고 있다.
NFC 기술을 통한 소비자 마케팅의 변화NXP는 향후 몇 년 내에 NFC가 우리 일상 생활에 상당한 변화를 가지고 올 것으로 기대하고 있다. 이는 시장 수치들만 봐도 충분히 짐작할 수 있다. 통신거리 100m 이상의 NFC 기반 단말기 제품들이 2012년에 상용화되었는데, ABI 리서치의 조사에 따르면 2014년경에는 NFC 단말기의 보급률이 5억대를 초과하여 2017년경에는 20억 대에 이를 것으로 전망되고 있다. 32비트 MCU 플랫폼 간의 마이그레이션지난 수년간, 단일 코어 플랫폼의 표준화를 통해 마이크로컨트롤러(MCU) 공급업체 간 디자인 마이그레이션을 간소화하기 위한 논의가 이루어져 왔다. 흥미로운 사실은 이 모든 논의 가운데 주변장치에 대한 언급이 없다는 것이다. 주변장치는 MCU 공급업체 간 애플리케이션 마이그레이션을 위하여 반드시 필요한 요소이다.
32비트 MCU 플랫폼 간의 마이그레이션지난 수년간, 단일 코어 플랫폼의 표준화를 통해 마이크로컨트롤러(MCU) 공급업체 간 디자인 마이그레이션을 간소화하기 위한 논의가 이루어져 왔다. 흥미로운 사실은 이 모든 논의 가운데 주변장치에 대한 언급이 없다는 것이다. 주변장치는 MCU 공급업체 간 애플리케이션 마이그레이션을 위하여 반드시 필요한 요소이다. 첨단 다상 인터리빙 부스트 컨버터를 위한 빠르고 간단한 솔루션2상 인터리빙 부스트 컨버터가 단상 컨버터에 비해 갖는 장점은 고효율 다상 인터리빙 컨버터에 대한 연구를 가속화시켰다. 2상 인터리빙 부스트 컨버터는 기존의 단일 대형 스테이지에 비해 보다 작은 2개의 스테이지를 병렬로 관리할 수 있다.
첨단 다상 인터리빙 부스트 컨버터를 위한 빠르고 간단한 솔루션2상 인터리빙 부스트 컨버터가 단상 컨버터에 비해 갖는 장점은 고효율 다상 인터리빙 컨버터에 대한 연구를 가속화시켰다. 2상 인터리빙 부스트 컨버터는 기존의 단일 대형 스테이지에 비해 보다 작은 2개의 스테이지를 병렬로 관리할 수 있다.
 NXP, 안전한 SDV 중앙 제어 위한 차량용 S32N55 프로세서 출시
NXP, 안전한 SDV 중앙 제어 위한 차량용 S32N55 프로세서 출시 팔로알토 네트웍스, AI 시대의 사이버 보안 주제로 ‘이그나이트 2024’ 행사 개최
팔로알토 네트웍스, AI 시대의 사이버 보안 주제로 ‘이그나이트 2024’ 행사 개최 탈레스 알레니아 스페이스, 국내 최초 정찰위성 ‘425사업’ 위성의 성공적 발사 지원
탈레스 알레니아 스페이스, 국내 최초 정찰위성 ‘425사업’ 위성의 성공적 발사 지원 가트너, 올해의 5가지 주요 거브테크(GovTech) 트렌드 발표
가트너, 올해의 5가지 주요 거브테크(GovTech) 트렌드 발표 슈퍼마이크로, X14 서버 제품군에 6세대 인텔 제온 프로세서 탑재 예정
슈퍼마이크로, X14 서버 제품군에 6세대 인텔 제온 프로세서 탑재 예정
- 이튼, 데이터 센터 사업의 연속성 보장하는 대용량 UPS ‘9395XR’ 국내 출시
- 이니텍, 보안성 강화한 기업용 생성형 AI 서비스 ‘시큐어 AI’ 출시
- 로지텍, 프리미엄 RGB 게이밍 마이크 ‘YETI GX’ 출시
- 삼텍, 부품 출시 설계 가속화 위해 SIBORG 도구 도입
- 로데슈바르즈, 다양한 전력 측정 요구사항을 완벽하게 충족하는 R&S NPA 컴팩트 전력 분석기 출시
- AMD, 새로운 기업용 AI PC 모바일 및 데스크톱 프로세서 공개
그래픽 / 영상
 결정론, 새로운 이더넷 애플리케이션을 열다
결정론, 새로운 이더넷 애플리케이션을 열다 AMD, 새로운 2세대 버설 적응형 SoC로 AI 기반 임베디드 시스템의 종단간 가속 지원
AMD, 새로운 2세대 버설 적응형 SoC로 AI 기반 임베디드 시스템의 종단간 가속 지원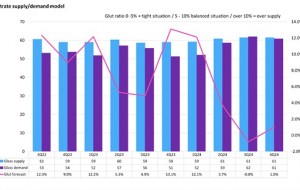 2024년, 디스플레이 글래스 산업 공급부족 우려
2024년, 디스플레이 글래스 산업 공급부족 우려
많이 본 뉴스
 슈퍼마이크로, 엔비디아 기반 풀스택 생성형 AI 슈퍼클러스터 3종 출시
슈퍼마이크로, 엔비디아 기반 풀스택 생성형 AI 슈퍼클러스터 3종 출시 알테라, 인텔에서 다시 FPGA 기업으로 독립
알테라, 인텔에서 다시 FPGA 기업으로 독립 원프레딕트, SFAW 2024에서 한국산업 디지털 전환 기여
원프레딕트, SFAW 2024에서 한국산업 디지털 전환 기여 Arm, AI 인프라 활성화 위한 Arm 네오버스 로드맵 업데이트 발표
Arm, AI 인프라 활성화 위한 Arm 네오버스 로드맵 업데이트 발표 피커링, 80W의 스위치를 제공하는 고전력 시리즈 144 리드 릴레이 출시
피커링, 80W의 스위치를 제공하는 고전력 시리즈 144 리드 릴레이 출시 네패스, 지멘스의 첨단 설계 솔루션으로 3D-IC 시대를 위한 IC 패키징 역량 확장
네패스, 지멘스의 첨단 설계 솔루션으로 3D-IC 시대를 위한 IC 패키징 역량 확장 어플라이드 머티어리얼즈, 옹스트롬 시대를 위한 패터닝 솔루션 포트폴리오 확대
어플라이드 머티어리얼즈, 옹스트롬 시대를 위한 패터닝 솔루션 포트폴리오 확대 인텔, 파운드리 사업 위한 재무 구조 개편 및 수익성 확대 방안 설정
인텔, 파운드리 사업 위한 재무 구조 개편 및 수익성 확대 방안 설정 피커링 인터페이스, 스위치 밀도를 두 배로 늘린 고전압 PXI 멀티플렉서 제품군 출시
피커링 인터페이스, 스위치 밀도를 두 배로 늘린 고전압 PXI 멀티플렉서 제품군 출시 헥사곤-한서대학교, 차세대 SW융합 인재 양성 위한 MOU 체결
헥사곤-한서대학교, 차세대 SW융합 인재 양성 위한 MOU 체결