
엔비디아(www.nvidia.co.kr , CEO 젠슨 황)는 아마존웹서비스(Amazon Web Services)의 새로운 EC2 P4d 인스턴스에 엔비디아 A100 텐서코어(Tensor Core) GPU가 탑재된다고 밝혔다.
AWS의 첫 GPU 인스턴스는 엔비디아 M2050과 함께 10년전에 출시됐다. 당시는 인공지능(AI)과 딥 러닝이 부상하기 전으로, 쿠다(CUDA) 기반 애플리케이션은 주로 과학 시뮬레이션을 가속화하는데 초점이 맞춰졌다. 이후 AWS는 K80, K520, M60, V100 및 T4를 포함하는 안정적인 클라우드 GPU 인스턴스를 추가했다.

새로운 P4d 인스턴스는 머신러닝 훈련 및 고성능컴퓨팅(HPC) 애플리케이션을 위해 AWS의 최고 성능과 비용 효율성을 제공하는 GPU 기반 플랫폼을 지원한다. 이는 기본 FP32 정밀도 대비 각각 FP16에서 최대 3배, T432에서 머신러닝 모델 훈련 시간을 최대 6배 단축한다. 또한 P4d 인스턴스는 탁월한 추론 성능을 제공한다. 지난달 MLPerf 추론 벤치마크에서 엔비디아 A100 GPU는 CPU 대비 최대 237배 빠른 성능을 보였다.
각각의 P4d 인스턴스는 8개의 엔비디아 A100 GPU로 구동되며, AWS 울트라클러스터즈(AWS UltraClusters)를 통해 고객은 AWS EFA(Elastic Fabric Adaptor)를 사용하여 한번에 4,000개 이상의 GPU에 대한 확장 가능한 온-디맨드 액세스를 얻을 수 있다. 또한, P4d는 400Gbps 네트워킹을 제공하고, NV링크(NVLink), NV스위치(NVSwitch), NCCL, GPUDirect RDMA 등의 엔비디아 기술을 통해 딥 러닝 훈련 워크로드를 더욱 가속화한다. AWS EFA를 통한 엔비디아 GPUDirect RDMA 기술로 CPU와 시스템 메모리를 통과하지 않고도 서버 간 GPU에서 GPU로 데이터를 전송해 낮은 레이턴시(지연시간) 네트워킹을 보장한다.
P4d 인스턴스는 아마존 ECS(Amazon Elastic Container Service), 아마존 EKS(Elastic Kubernetes Service), AWS 패러렐클러스터(AWS ParallelCluster), 아마존 세이지메이커(Amazon SageMaker) 등의 AWS 소프트웨어를 활용한다. 이 외에도 P4d 인스턴스는 HPC 애플리케이션, AI 프레임워크, 사전 훈련된 모델, 헬름 차트 및 텐서RT(TensorRT)와 트리톤 추론 서버(Triton Inference Server)와 같은 소프트웨어를 포함한 NGC에서 사용할 수 있는 최적화된 컨테이너형 소프트웨어를 모두 활용할 수 있다.
P4d 인스턴스는 현재 미국 동부와 서부에서 사용할 수 있으며, 곧 이용가능 지역이 추가될 예정이다. 세이빙 플랜(Savings Plans), 리저브드 인스턴스(Reserved Instances)와 함께 온-디맨드 또는 스팟 인스턴스(Spot Instances)로 구매할 수 있다.
GPU 클라우드 컴퓨팅의 역사가 시작된 10년 동안 100엑사플롭 이상의 AI 컴퓨팅이 시장에 출시됐다. 엔비디아 A100 GPU 기반의 아마존 EC2 P4d 인스턴스가 출시됨에 따라 새로운 GPU 클라우드 컴퓨팅 시장이 열릴 예정이다. 엔비디아와 AWS는 다양한 애플리케이션들의 AI 경계가 계속 확장하도록 지원하고 있다.
저작권©올포칩 미디어. 무단전재 및 재배포를 금지합니다.
- 다쏘시스템, ‘솔리드웍스 2021’ 출시이번 솔리드웍스 2021은 업무 생산성을 높일 수 있도록 설계, 문서화, 데이터 관리, 검증 등 기능과 워크플로우를 개선했다. 또한, 컨셉 및 제품 설계, 해석, 데이터 관리, 생산에 이르는 제조 전 과정을 아우르는 클라우드 기반 솔루션인 ‘3D익스피리언스웍스(3DEXPERIENCE WORKS)’ 포트폴리오와의 연계를 통해 협업 기능을 강화했다.
 SAP 코리아, SAP HANA 출시 10주년 맞아 고객 데이터를 가치 있는 자산으로의 전환 지원 확대SAP의 첫 한국 데이터센터 설립은 총 2단계로 진행된다. SAP 코리아는 데이터센터 설립과 함께 오는 2021년 2분기까지 SAP 클라우드 플랫폼(SAP Cloud Platform), SAP 분석 클라우드(SAP Analytics Cloud) 및 SAP HANA 클라우드 솔루션을 국내 기업에 제공하고, 이어서 추가적인 SAP 비즈니스 테크놀로지 플랫폼(Business Technology Platform, 이하 BTP)를 제공한다는 계획이다.
SAP 코리아, SAP HANA 출시 10주년 맞아 고객 데이터를 가치 있는 자산으로의 전환 지원 확대SAP의 첫 한국 데이터센터 설립은 총 2단계로 진행된다. SAP 코리아는 데이터센터 설립과 함께 오는 2021년 2분기까지 SAP 클라우드 플랫폼(SAP Cloud Platform), SAP 분석 클라우드(SAP Analytics Cloud) 및 SAP HANA 클라우드 솔루션을 국내 기업에 제공하고, 이어서 추가적인 SAP 비즈니스 테크놀로지 플랫폼(Business Technology Platform, 이하 BTP)를 제공한다는 계획이다. AMD, 2020년 3분기 x86 시장 점유율 상승세 기록시장 조사 전문기관 머큐리 리서치(Mercury Research)가 발표한 최근 자료에 따르면, AMD의 2020년 3분기 x86 CPU 시장 점유율이 22.4%를 기록한 것으로 나타났다. 특히 AMD는 모든 주요 사업 부문에서 해마다 매분기 강력한 성장세를 지속하고 있는 것으로 조사됐다. AMD는 전체 x86 CPU 시장 점유율에서 22.4% 기록하며, 2분기 대비 4.1 포인트, 전년 대비 6.3 포인트 성장세를 기록했다. 이를 통해 2007년 4분기 이후 최고 기록을 갱신했다.
AMD, 2020년 3분기 x86 시장 점유율 상승세 기록시장 조사 전문기관 머큐리 리서치(Mercury Research)가 발표한 최근 자료에 따르면, AMD의 2020년 3분기 x86 CPU 시장 점유율이 22.4%를 기록한 것으로 나타났다. 특히 AMD는 모든 주요 사업 부문에서 해마다 매분기 강력한 성장세를 지속하고 있는 것으로 조사됐다. AMD는 전체 x86 CPU 시장 점유율에서 22.4% 기록하며, 2분기 대비 4.1 포인트, 전년 대비 6.3 포인트 성장세를 기록했다. 이를 통해 2007년 4분기 이후 최고 기록을 갱신했다. 듀폰 강상호 사장, ‘2020년 외국기업의 날’ 은탑산업훈장 수상듀폰은 올해 초 국내 자회사인 롬엔드하스 전자재료 코리아를 통해 충청남도 천안에 EUV용 포토레지스트와 CMP패드의 개발·생산 시설 투자를 발표했다. 강상호 사장은 반도체 핵심 재료의 국내 생산과 신규 고용을 창출하고, 국내 반도체 산업의 글로벌 경쟁력 강화에 기여한 공로를 인정받아 은탑산업훈장을 수상하게 되었다.
듀폰 강상호 사장, ‘2020년 외국기업의 날’ 은탑산업훈장 수상듀폰은 올해 초 국내 자회사인 롬엔드하스 전자재료 코리아를 통해 충청남도 천안에 EUV용 포토레지스트와 CMP패드의 개발·생산 시설 투자를 발표했다. 강상호 사장은 반도체 핵심 재료의 국내 생산과 신규 고용을 창출하고, 국내 반도체 산업의 글로벌 경쟁력 강화에 기여한 공로를 인정받아 은탑산업훈장을 수상하게 되었다. 인피니언의 CoolSiC MOSFET, 독일 EA Elektro-Automatik의 전기 드라이브트레인 테스트 용 양방향 파워서플라이에 채택EA Elektro-Automatik의 디바이스는 출력 전압 또는 출력 전류의 1/3로도 최대 전력을 제공한다. 자동차 배터리 충전과 방전이 좋은 예이다. 배터리 전압이 상승하거나 하강하더라도 전류가 자동으로 조절하여 최대 전력을 제공한다. 이러한 유연성으로 다양한 전자 부품을 테스트할 때 필요한 많은 장비를 줄일 수 있다.
인피니언의 CoolSiC MOSFET, 독일 EA Elektro-Automatik의 전기 드라이브트레인 테스트 용 양방향 파워서플라이에 채택EA Elektro-Automatik의 디바이스는 출력 전압 또는 출력 전류의 1/3로도 최대 전력을 제공한다. 자동차 배터리 충전과 방전이 좋은 예이다. 배터리 전압이 상승하거나 하강하더라도 전류가 자동으로 조절하여 최대 전력을 제공한다. 이러한 유연성으로 다양한 전자 부품을 테스트할 때 필요한 많은 장비를 줄일 수 있다. KT, 키자니아에 자율주행 방역 서비스 시범운용KT가 이번에 키자니아에서 시범 운용하는 자율주행 방역 서비스는 지난달 KT East 사옥에서 첫 선을 보인 자율주행 방역 로봇 ‘캠피온’을 통해 제공된다. 캠피온은 KT가 이번 시범운용을 위해 초기 단계부터 협업한 벤처기업 ‘도구공간’과 함께 기획한 로봇이다. 여기에 자율 주행 방역 서비스를 클라우드 상에서 원격으로 제어하는 서비스형 관제 소프트웨어(SaaS)인 KT ‘모빌리티 메이커스’도 활용된다.
KT, 키자니아에 자율주행 방역 서비스 시범운용KT가 이번에 키자니아에서 시범 운용하는 자율주행 방역 서비스는 지난달 KT East 사옥에서 첫 선을 보인 자율주행 방역 로봇 ‘캠피온’을 통해 제공된다. 캠피온은 KT가 이번 시범운용을 위해 초기 단계부터 협업한 벤처기업 ‘도구공간’과 함께 기획한 로봇이다. 여기에 자율 주행 방역 서비스를 클라우드 상에서 원격으로 제어하는 서비스형 관제 소프트웨어(SaaS)인 KT ‘모빌리티 메이커스’도 활용된다.- 텍트로닉스, 2세대 IsoVu 절연 오실로스코프 프로브 출시이 제품은 2016년 시장에 첫 출시된 이래 폼팩터 및 기능이 대폭 개선된 제품이다. 새로워진 2세대 IsoVu 프로브는 1세대의 1/5 사이즈로 작아진 크기는 물론 더 편리해진 사용법, 전기적 퍼포먼스 향상으로 절연 프로브 기술이 요구되는 전원 시스템 설계 시장에서 적극적으로 사용될 수 있다
- ST, 압전 MEMS 시장 확대 위해 A*STAR 및 알박과 협력하여 싱가포르에 세계 최초 ‘LiF(Lab-in-Fab)’ 설립이번 협력은 ST 싱가포르의 제조 공정 포트폴리오를 강화하고, 새로운 유망 애플리케이션 분야에서의 압전 MEMS 액추에이터 채택을 가속화할 것이다. 여기에는 스마트 안경을 위한 MEMS 미러와 AR 헤드셋 및 라이다(LiDAR) 시스템, 새로운 의료 애플리케이션용 PMUT(Piezoelectric Micromachined Ultrasonic Transducer), 상업용 및 산업용 3D 프린팅을 지원하는 압전 헤드(Piezo Head) 등이 있다.
 마우저, 설계 과정 전반 지원하는 기술 지원 센터 공개옴의 법칙은 회로에 흐르는 전류는 두 지점 사이에 인가된 전압에 비례한다는 법칙이다. 마우저의 온라인 옴의 법칙 계산기는 필요한 자료를 쉽고 빠르고 찾을 수 있어 엔지니어의 시간을 절약할 수 있다. 회로 내 임의의 두 지점값을 입력하면 나머지 값을 쉽게 구할 수 있기 때문에 설계 과정에서 소비되는 시간을 줄일 수 있는 것이다.
마우저, 설계 과정 전반 지원하는 기술 지원 센터 공개옴의 법칙은 회로에 흐르는 전류는 두 지점 사이에 인가된 전압에 비례한다는 법칙이다. 마우저의 온라인 옴의 법칙 계산기는 필요한 자료를 쉽고 빠르고 찾을 수 있어 엔지니어의 시간을 절약할 수 있다. 회로 내 임의의 두 지점값을 입력하면 나머지 값을 쉽게 구할 수 있기 때문에 설계 과정에서 소비되는 시간을 줄일 수 있는 것이다. 인텔, 아이리스 Xe 맥스 외장그래픽 및 딥 링크로 기술혁신 확대인텔 아이리스 Xe 맥스 외장그래픽은 11세대 인텔 코어 모바일 프로세서에 탑재된 인텔 아이리스 Xe 그래픽과 동일한 Xe-LP 마이크로아키텍처를 기반으로 한다. 아울러, 인텔이 외장그래픽 시장에 진출하기 위한 전략의 일환으로 개발한 인텔 최초의 Xe 기반 외장 그래픽 처리 장치(GPU)다. 인텔 아이리스 Xe 맥스 플랫폼은 인텔 어댑틱스(Intel Adaptix) 툴킷의 일부인 Intel Deep Link 기술을 탑재하고 PCIe 4세대 기술을 지원하며, 씬앤라이트 노트북에서 컨텐츠 제작에 필요한 성능을 제공한다.
인텔, 아이리스 Xe 맥스 외장그래픽 및 딥 링크로 기술혁신 확대인텔 아이리스 Xe 맥스 외장그래픽은 11세대 인텔 코어 모바일 프로세서에 탑재된 인텔 아이리스 Xe 그래픽과 동일한 Xe-LP 마이크로아키텍처를 기반으로 한다. 아울러, 인텔이 외장그래픽 시장에 진출하기 위한 전략의 일환으로 개발한 인텔 최초의 Xe 기반 외장 그래픽 처리 장치(GPU)다. 인텔 아이리스 Xe 맥스 플랫폼은 인텔 어댑틱스(Intel Adaptix) 툴킷의 일부인 Intel Deep Link 기술을 탑재하고 PCIe 4세대 기술을 지원하며, 씬앤라이트 노트북에서 컨텐츠 제작에 필요한 성능을 제공한다. 지브라 테크놀로지스, ‘2020 굿 디자인 어워드’ 수상지브라 테크놀로지스(Zebra Technologies)는 자사의 MC9300 울트라 러기드 모바일 터치 컴퓨터, RS5100 싱글 핑거 블루투스 링 스캐너, DS9308 바코드 스캐너가 상업 및 산업 디자인 부문에서 권위 있는 굿 디자인 어워드(Good Design Award)를 수상했다고 발표했다.
지브라 테크놀로지스, ‘2020 굿 디자인 어워드’ 수상지브라 테크놀로지스(Zebra Technologies)는 자사의 MC9300 울트라 러기드 모바일 터치 컴퓨터, RS5100 싱글 핑거 블루투스 링 스캐너, DS9308 바코드 스캐너가 상업 및 산업 디자인 부문에서 권위 있는 굿 디자인 어워드(Good Design Award)를 수상했다고 발표했다. 포티넷코리아, 한국형사정책연구원에 포티넷 ‘랜 엣지’(LAN edge)’ 솔루션 구축한국형사정책연구원은 방화벽과 스위치, 무선AP를 통합 제공하여 지능적이고 진화된 무선망 보안과 통합 관리 기능을 지원하는 포티넷의 ‘랜 엣지(LAN edge)’ 솔루션을 선택했다. 특히 ‘가트너 매직 쿼드런트'에서 방화벽 부분 10년 연속 리더로 선정되는 등 높은 성능과 안정성, 신뢰성을 갖추고 있으며, 운영 메뉴얼이 간편하고 필요에 따라 자유자재로 추가 및 변경이 가능한 GUI를 제공하여 관리 효율성을 극대화할 수 있다는 점을 높이 평가했다.
포티넷코리아, 한국형사정책연구원에 포티넷 ‘랜 엣지’(LAN edge)’ 솔루션 구축한국형사정책연구원은 방화벽과 스위치, 무선AP를 통합 제공하여 지능적이고 진화된 무선망 보안과 통합 관리 기능을 지원하는 포티넷의 ‘랜 엣지(LAN edge)’ 솔루션을 선택했다. 특히 ‘가트너 매직 쿼드런트'에서 방화벽 부분 10년 연속 리더로 선정되는 등 높은 성능과 안정성, 신뢰성을 갖추고 있으며, 운영 메뉴얼이 간편하고 필요에 따라 자유자재로 추가 및 변경이 가능한 GUI를 제공하여 관리 효율성을 극대화할 수 있다는 점을 높이 평가했다. KT파워텔, 국제 표준 LTE 무전 서비스 ‘파워톡 3.0’ 출시KT파워텔은 지난 `14년 LTE 무전통신 플랫폼 ‘파워톡 2.0’을 자체 기술력으로 개발하여 기업 업무용 무전 서비스를 제공해왔다. 이번에 새롭게 출시한 ‘파워톡 3.0’은 3GPP의 국제 무전 표준규격에 맞춰 개발한 것으로 서비스의 안정성, 보안성, 호환성을 대폭 강화했다. 국가 재난망 연동이 가능하며 글로벌 시장에서도 바로 적용할 수 있어 무전통신 시장 확대가 기대된다.
KT파워텔, 국제 표준 LTE 무전 서비스 ‘파워톡 3.0’ 출시KT파워텔은 지난 `14년 LTE 무전통신 플랫폼 ‘파워톡 2.0’을 자체 기술력으로 개발하여 기업 업무용 무전 서비스를 제공해왔다. 이번에 새롭게 출시한 ‘파워톡 3.0’은 3GPP의 국제 무전 표준규격에 맞춰 개발한 것으로 서비스의 안정성, 보안성, 호환성을 대폭 강화했다. 국가 재난망 연동이 가능하며 글로벌 시장에서도 바로 적용할 수 있어 무전통신 시장 확대가 기대된다.- 유니즌, 디지털 뉴딜 ‘데이터 댐’ 사업 수행기업 선정정부가 지난 7월 발표한 디지털 뉴딜의 10대 대표과제 중 하나인 ‘데이터 댐’은 디지털 전환을 선도하기 위해 14만여 개 공공데이터를 민간이 활용할 수 있도록 기반을 마련하기 위한 사업이다. 데이터 댐은 △인공지능(AI) 학습용 데이터 구축 △AI 바우처 △AI데이터 가공 바우처 사업 △AI 융합 프로젝트(AI+X) △클라우드 플래그십 프로젝트 △클라우드 이용 바우처 사업 △빅데이터 플랫폼 및 센터 구축 등 7개 사업으로 구성돼 있다.
 IMDT와 Hailo가 합작하여 최고의 실시간 성능을 위한 엣지 AI 솔루션 출시
IMDT와 Hailo가 합작하여 최고의 실시간 성능을 위한 엣지 AI 솔루션 출시 콩가텍, 인텔 코어 i3 및 인텔 아톰 x7000RE 프로세서 탑재 SMARC 모듈 출시
콩가텍, 인텔 코어 i3 및 인텔 아톰 x7000RE 프로세서 탑재 SMARC 모듈 출시 인텔, 세계 최대규모 뉴로모픽 시스템 공개
인텔, 세계 최대규모 뉴로모픽 시스템 공개 마이크로칩, 항공기 전기화 전화를 간소화하는 통합 구동 파워 솔루션 출시
마이크로칩, 항공기 전기화 전화를 간소화하는 통합 구동 파워 솔루션 출시 텔레다인르크로이, 광범위한 통신 기술 데이터를 원활하게 포착하는 프론트라인 X500e 출시
텔레다인르크로이, 광범위한 통신 기술 데이터를 원활하게 포착하는 프론트라인 X500e 출시
- TTTech Auto, 복잡한 소프트웨어 통합을 혁신할 차세대 스케줄러 ‘MotionWise Schedule’ 출시
- 아이스아이, 글로벌 SAR 리더십 확장을 위한 기업의 성장 펀딩 라운드 초과 달성
- 오나인솔루션즈, 생성형 AI 기술 적용해 ‘o9 Digital Brain’ 플랫폼 강화
- 테스트웍스, 차세대 반도체 개발 지원 시험-검증 통합 관리 솔루션 발표
- NXP, 안전한 SDV 중앙 제어 위한 차량용 S32N55 프로세서 출시
- 팔로알토 네트웍스, AI 시대의 사이버 보안 주제로 ‘이그나이트 2024’ 행사 개최
그래픽 / 영상
 결정론, 새로운 이더넷 애플리케이션을 열다
결정론, 새로운 이더넷 애플리케이션을 열다 AMD, 새로운 2세대 버설 적응형 SoC로 AI 기반 임베디드 시스템의 종단간 가속 지원
AMD, 새로운 2세대 버설 적응형 SoC로 AI 기반 임베디드 시스템의 종단간 가속 지원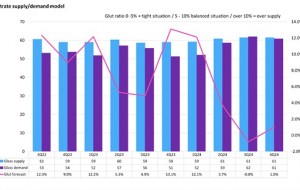 2024년, 디스플레이 글래스 산업 공급부족 우려
2024년, 디스플레이 글래스 산업 공급부족 우려
많이 본 뉴스
 한국마이크로소프트, 개발자들의 축제 ‘Microsoft AI Tour in Seoul’ 개최
한국마이크로소프트, 개발자들의 축제 ‘Microsoft AI Tour in Seoul’ 개최 ST, 탁월한 그래픽 성능을 지원하는 최신 STM32 마이크로컨트롤러 출시
ST, 탁월한 그래픽 성능을 지원하는 최신 STM32 마이크로컨트롤러 출시 레노버, AI PC 혁신의 미래 제시
레노버, AI PC 혁신의 미래 제시 TI, 임베디드 월드2024에서 스마트하고 지속 가능한 미래를 위한 기술 소개
TI, 임베디드 월드2024에서 스마트하고 지속 가능한 미래를 위한 기술 소개 코닝 반 홀(Vaughn Hall) 한국 총괄사장, 코닝의 한국 지역 법인 통합 운영
코닝 반 홀(Vaughn Hall) 한국 총괄사장, 코닝의 한국 지역 법인 통합 운영 헥사곤-스맥, 스마트 제조 기술 개발 위한 MOU 체결
헥사곤-스맥, 스마트 제조 기술 개발 위한 MOU 체결 유니버설 로봇, 매스웍스 커넥션즈 프로그램 참여로 파트너십 강화
유니버설 로봇, 매스웍스 커넥션즈 프로그램 참여로 파트너십 강화 헥사곤, 창원 소재 헥사곤 이노베이션 센터 개관
헥사곤, 창원 소재 헥사곤 이노베이션 센터 개관 키사이트, 삼성 파운드리 8LPP 공정 기술 전자기 시뮬레이션 소프트웨어 인증
키사이트, 삼성 파운드리 8LPP 공정 기술 전자기 시뮬레이션 소프트웨어 인증 마우저, 웨어러블 리소스 센터를 통해 엔지니어를 위한 포괄적인 콘텐츠 제공
마우저, 웨어러블 리소스 센터를 통해 엔지니어를 위한 포괄적인 콘텐츠 제공